为什么需要一致性哈希
首先考虑一个普通的数据分区场景,例如分布式缓存,由于缓存很大,一台机器已经无法容纳这么多的缓存,这时就需要将缓存分散到不同的机器上。这时比较常用的方式就是对每个 key 计算哈希值,然后按机器数据取模,得到对应机器的编号,从而将数据分散存储。但是按机器数取模这种方式在进行横向扩展时需要按新的机器数重新取模并对数据进行迁移,每台机器上的数据都有可能迁移到另一台机器上,效率比较低。
一致性哈希在哈希表的大小(上面的机器数)变化时,可以保证只有 n/m 的 keys 需要重新映射,其中 n 是 keys 的数量, m 是哈希槽的的个数。
原理
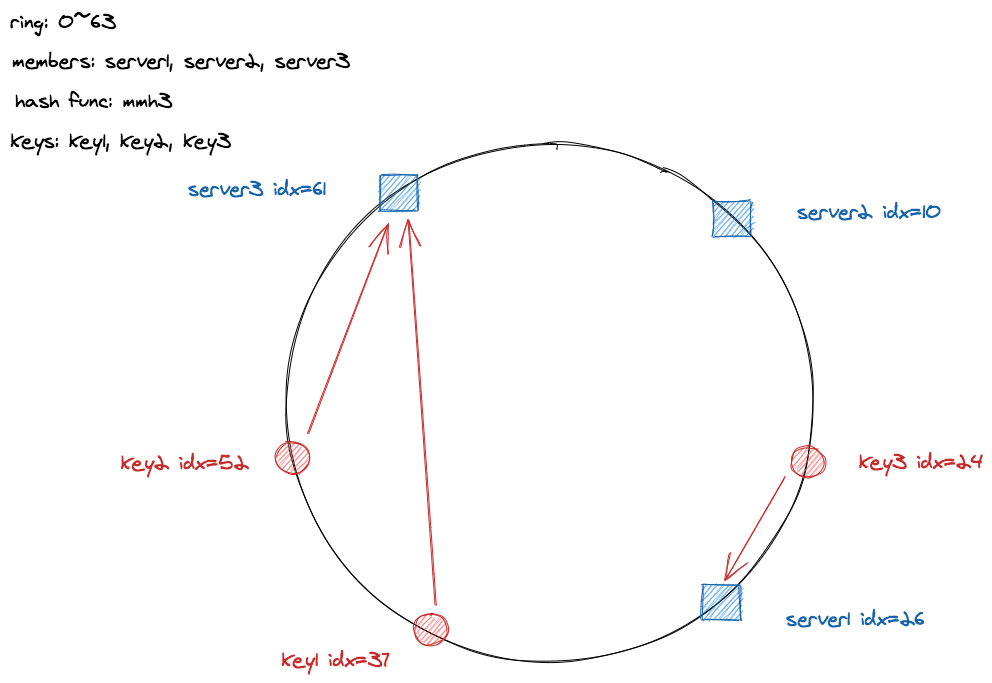
和采用开放寻址法解决哈希冲突的普通哈希表一样,哈希槽呈环形结构,上图中哈希槽的个数为 64 个,实际应用中会大很多一般是 2^32 个或者 2^64 个,这样可以取满哈希函数的值域,按照上面 n/m 的公式,哈希槽的个数越多,意味着每次调整时重新映射的 keys 越少。
映射的方式为,首先将 servers 映射到哈希环上,然后将 keys 映射的哈希环上,根据 keys 在哈希槽中的位置 idx 找到不小于它的第一个 server,建立 key 与 server 之间的关系。以上图为例,首先用 murmurhash3 哈希函数对 server1,server2,server3 求哈希值按哈希槽个数取模得到其对应的 idx:26、10、61,加入 key1,key2,key3 时按同样的方式得到其对应的 idx:37、52、 24,然后找到不小于它的第一个 server 即 key1 对应 server3,key2 对应 server3,key3 对应 server1。
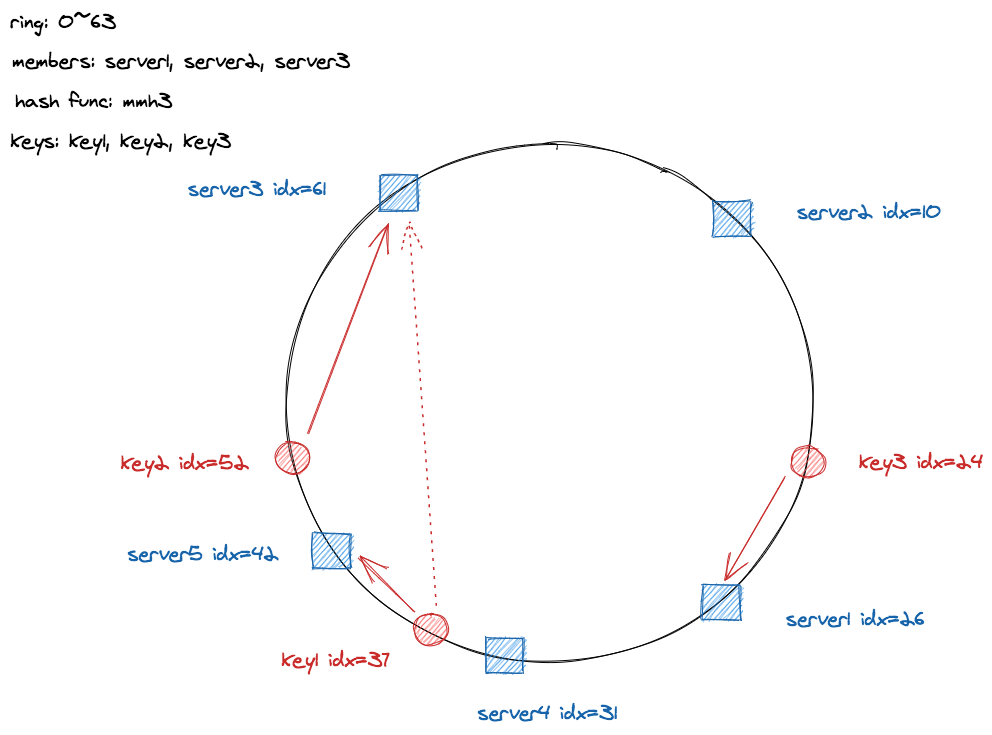
接下来加入两个 server:server4 和 server5,分别得到其 idx: 31 和 42,由于 (26, 31] 的范围内没有 key ,所以 server4 加入不需要重新映射,server5 的加入则会导致 (32, 42] 范围内的 key 需要从原来的 server3 迁移到 server5 上。 key1 的 idx 为 37, 原来映射到 server3 上,由于 server5 的加入需要从 server3 迁移到 server5。删除一个 server 也是类似的,比如删除 server5 那么 server5 上的 key 需要迁移到 server3。虽然增删节点仍然有数据迁移的操作,但是对比普通的哈希取模方式减少了需要迁移数据的量,原来需要迁移所有的哈希槽上的数据,现在只需要迁移与增删节点相关联的数据即可。
另外还有一个问题是数据分布不均匀问题,server 在哈希环中分布不均匀会导致某些 server 所负责的 key 较多,而另一些所负责的 key 较少,在删节点时也可能会导致其下一个节点承载的数据量瞬间升高。那么怎么解决这个问题呢?一致性哈希解决的方式是通过增加虚拟节点,也就是让哈希环分布尽可能多的节点,节点足够多的话,只要哈希函数是均匀分布的,那么节点也会均匀分布在哈希环上,此时一个节点删除以后,由于其对应的每个虚拟节点的下一个节点不会是同一个节点的虚拟节点,其数据就会分散到不同的节点上,而不是只分布其对应的下一个节点上。
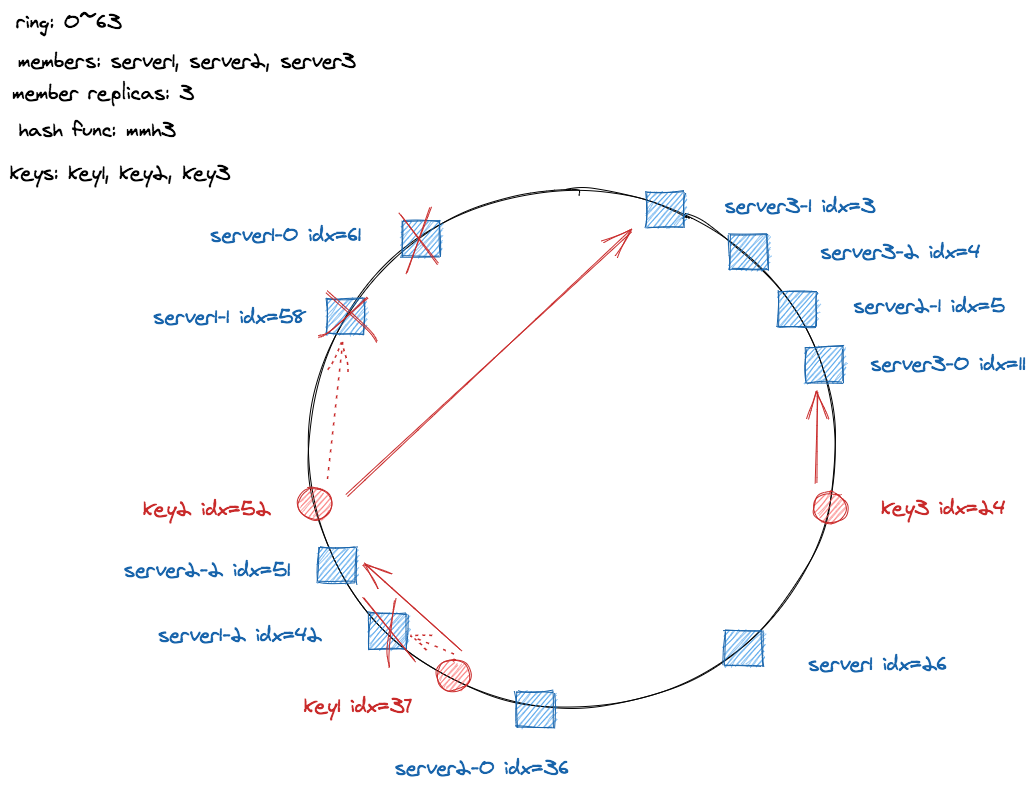
如上图所示,每个 server 有三个副本,即虚拟节点,当移除 server1 时,server1 上的 key1 和 key2 会分别重新迁移到 server2 和 server3 ,不会像之前一样都迁移到 server3 。当然这里的图上的分布依然不是十分均匀,原因是虚拟节点的个数不够多,如果虚拟节点足够多的话,server 在哈希环上的分布会是均匀的。
实现
这里研究一下 buraksezer/consistent 的实现。
与上面基本原理中描述的不同的是,这里的实现增加一个中间层 parttions ,不同的 key 会先哈希到 partition,partition 再映射到相应的节点上。
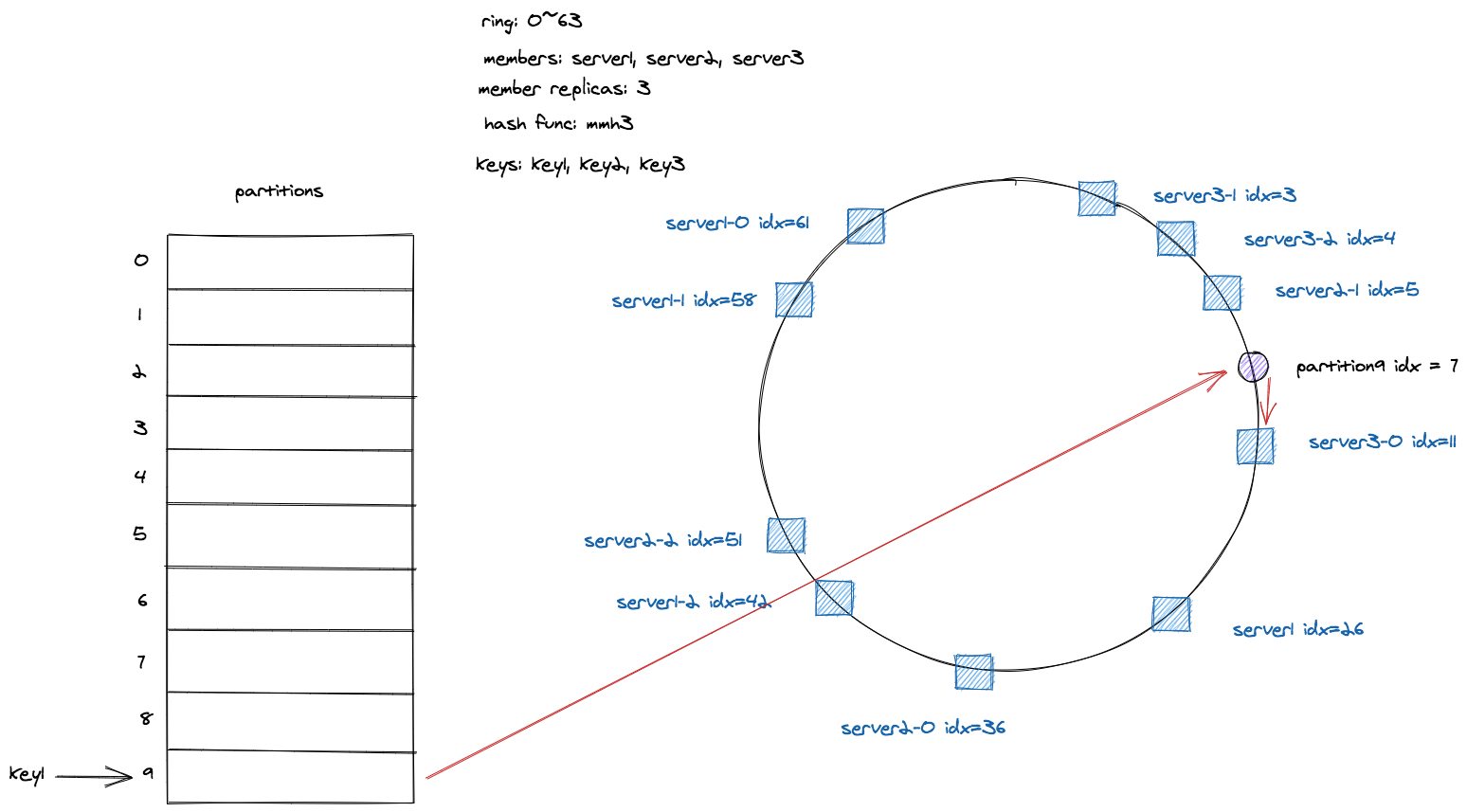
首先来看下基本的组成。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// Consistent holds the information about the members of the consistent hash circle.
type Consistent struct {
mu sync.RWMutex
config Config
hasher Hasher
sortedSet []uint64 //节点下标,已排好序,便于对某个 parttion 哈希得到相应下标后找到其邻近的节点
partitionCount uint64 //分区数量,如果 key 比较多,可以设置大一些
loads map[string]float64 // 每个节点对应的对应的负载
members map[string]*Member // 节点
partitions map[int]*Member // 通过 partition id 找到其对应节点
ring map[uint64]*Member // 哈希环
}
|
初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// New creates and returns a new Consistent object.
func New(members []Member, config Config) *Consistent {
c := &Consistent{
config: config,
members: make(map[string]*Member),
partitionCount: uint64(config.PartitionCount),
ring: make(map[uint64]*Member),
}
if config.Hasher == nil {
panic("Hasher cannot be nil")
}
// TODO: Check configuration here
c.hasher = config.Hasher
for _, member := range members {
c.add(member)
}
if members != nil {
c.distributePartitions()
}
return c
}
|
add。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func (c *Consistent) add(member Member) {
// 多少个副本构造出多少个节点
for i := 0; i < c.config.ReplicationFactor; i++ {
key := []byte(fmt.Sprintf("%s%d", member.String(), i))
h := c.hasher.Sum64(key)
c.ring[h] = &member
// 将哈希值记录下来 便于后面排序
c.sortedSet = append(c.sortedSet, h)
}
// 对哈希值排序
sort.Slice(c.sortedSet, func(i int, j int) bool {
return c.sortedSet[i] < c.sortedSet[j]
})
// parttion 可以通过节点名找到真正的节点
c.members[member.String()] = &member
}
|
distributePartitions 将 partition 映射到哈希环上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func (c *Consistent) distributePartitions() {
loads := make(map[string]float64)
partitions := make(map[int]*Member)
bs := make([]byte, 8)
for partID := uint64(0); partID < c.partitionCount; partID++ {
binary.LittleEndian.PutUint64(bs, partID)
key := c.hasher.Sum64(bs)
// 二分查找邻近节点的下标
idx := sort.Search(len(c.sortedSet), func(i int) bool {
return c.sortedSet[i] >= key
})
if idx >= len(c.sortedSet) {
idx = 0
}
// 将 partition 映射到查找的节点上,考虑 load 因素
c.distributeWithLoad(int(partID), idx, partitions, loads)
}
c.partitions = partitions
c.loads = loads
}
|
distributeWithLoad。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// AverageLoad exposes the current average load.
// 负载上限,config.Load 知道一个节点最多可以容纳多少个 partition
func (c *Consistent) AverageLoad() float64 {
avgLoad := float64(c.partitionCount/uint64(len(c.members))) * c.config.Load
return math.Ceil(avgLoad)
}
func (c *Consistent) distributeWithLoad(partID, idx int, partitions map[int]*Member, loads map[string]float64) {
avgLoad := c.AverageLoad()
var count int
for {
count++
// 所有的节点都已超出负载
if count >= len(c.sortedSet) {
// User needs to decrease partition count, increase member count or increase load factor.
panic("not enough room to distribute partitions")
}
i := c.sortedSet[idx]
member := *c.ring[i]
load := loads[member.String()]
if load+1 <= avgLoad { //当前节点还可以未超载
partitions[partID] = &member
loads[member.String()]++
return
}
// 当前节点已超载,尝试下一个节点
idx++
if idx >= len(c.sortedSet) {
idx = 0
}
}
}
|
其余的部分基本都是以上面几个为基础来实现的。这个实现有一点不足就是不支持带权节点,当然要实现带权节点也不难,只需要要在添加节点时加上权重参数,然后根据权重创建不同数量的虚拟节点即可。
Author
Hao
LastMod
2021-04-04
License
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可