时间轮定时器
Contents
定时器
定时器可以在未来某个时间执行一个或多个任务。定时器的应用非常广泛比如模拟生活中的定时器,调度,流控,熔断,后台定时监控,超时控制等等。定时器的功能基本包括三个,插入定时任务,移除已过期的任务,驱动定时器即检测任务是否到期需要执行。
定时器器的几种实现方式
链表
.5e492l6c1nc.png)
- 插入定时任务时从链表头部或尾部插入,时间复杂度 O(1) 。
- 检测任务是否到期需要遍历链表找到过期的任务执行,时间复杂度 O(n)。
- 移除过期的任务只须在链表中删除对应元素,时间复杂度 O(1)。
有序链表
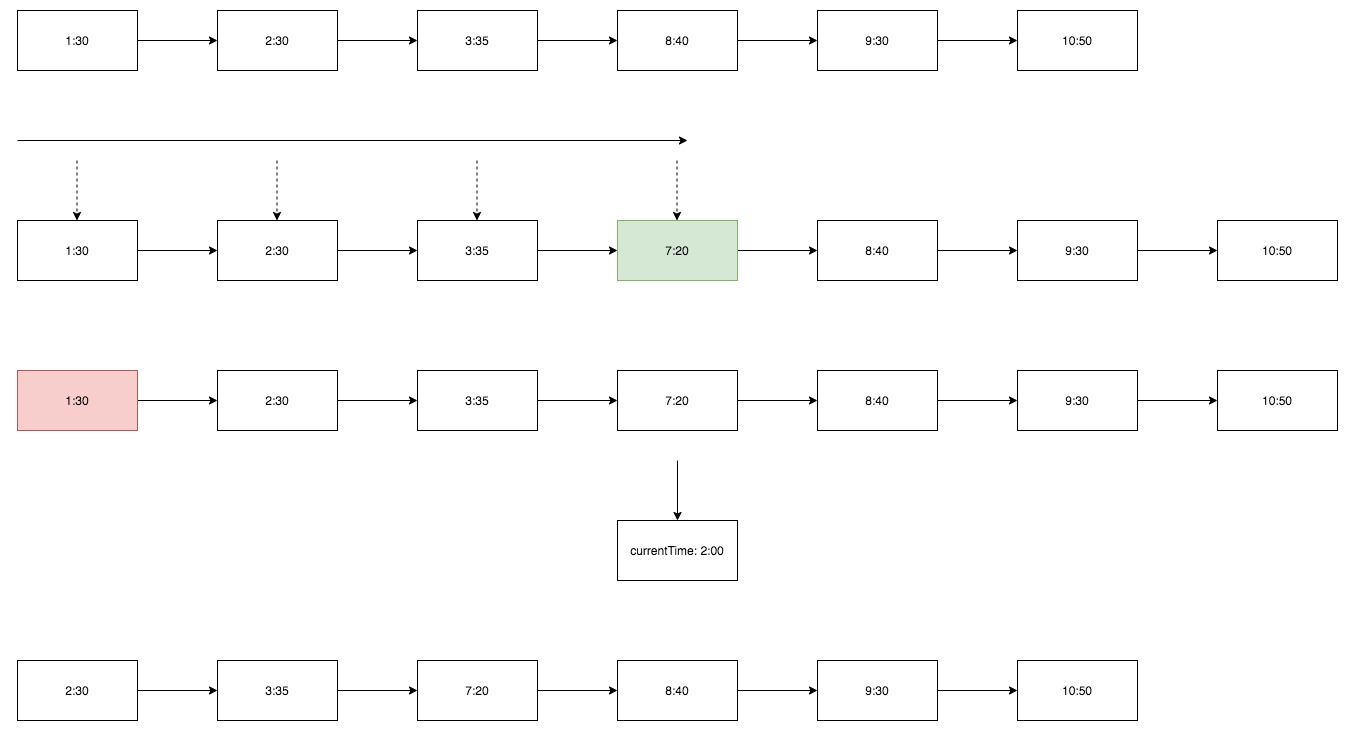
- 插入时需要保持有序,时间复杂度 O(n)。
- 检测任务是否到期只需要遍历到没有过期的任务就停止,时间复杂度 O(1)。
- 删除时间复杂度 O(1)。
二叉堆
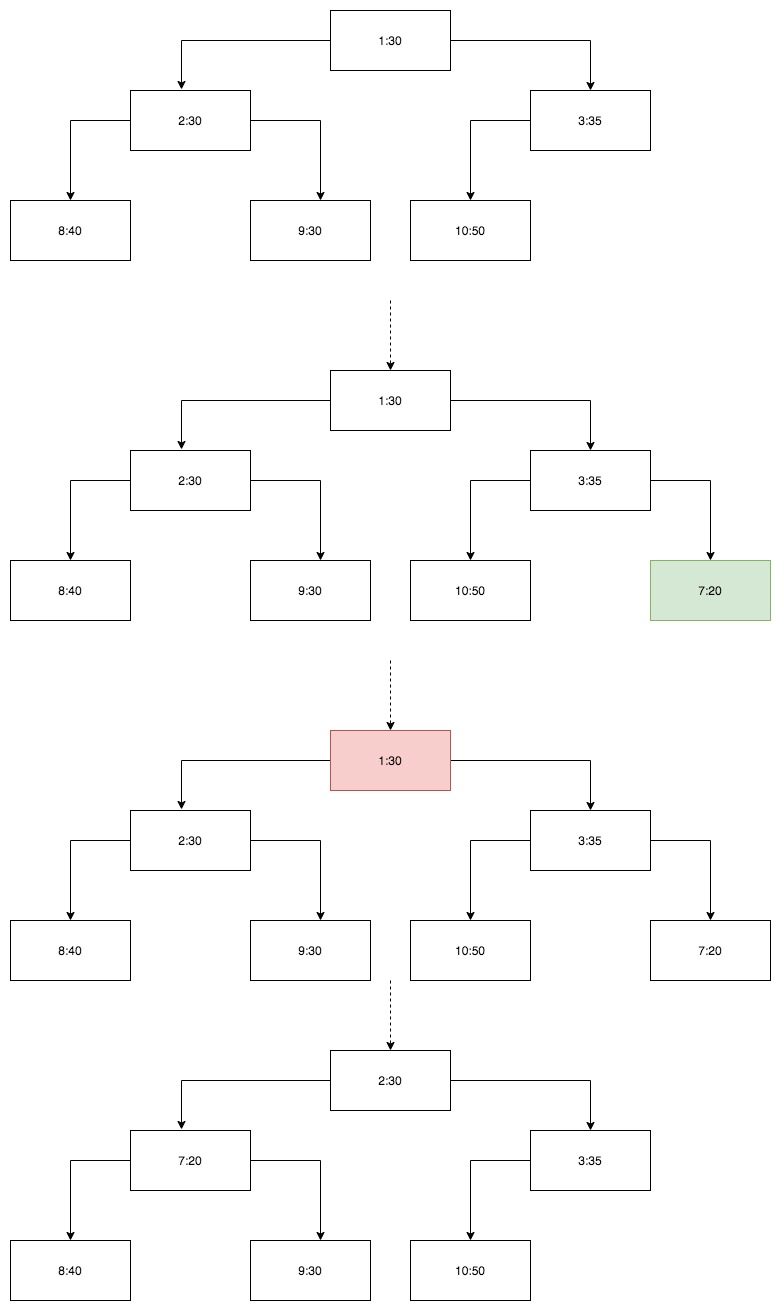
- 插入任务的时间复杂度为 O(logn)。
- 检测任务是否到期只需检测堆顶元素,时间复杂度为 O(1)。
- 删除元素后需要保持堆性质,时间复杂度为 O(logn)。
有序链表和二叉堆的性能似乎已经足够好了,那么还有没更好的选择呢?答案是有的,那就是时间轮定时器,其插入,删除,检测的时间复杂度都可以达到常数时间复杂度,在海量定时任务场景有很大的性能优势。
普通时间轮定时器
.kjtgp5ia27.jpg)
- 时间轮的结构和钟表的结构很类似,有一个环形数组组成,每个数组的元素代表某个时间区间,如果这个时间区间和当前的时间对比已经过期了,就会取出其中的任务执行。
- 插入任务时,首先通过延迟时间计算出要过期的绝对时间,然后放到相应的
bucket中,这里bucket中的元素表示 2:30 + i 秒,只是为了画图方便。例如延迟 2s 的任务其过期时间是 2:32 ,当前时间是 2:30 ,那么它应该放入 i = 2 的bucket中 (在实际的实现中只需特定时间过期的任务放到特定的bucket中就行)。 - 检查任务由后台线程进行检测,每次
currentTime向前走,过期的bucket中的任务就会取出来执行。例如当currentTime到了 2:32 ,那么 2:30 + 2 的这个bucket就过期了,可以取出来执行。 - 一旦取出任务执行后,那么这个
bucket就空出来了可以进行复用,例如 2:30 + 0,2:30 + 1 这两个bucket可以被 2:30 + 16,2:30 + 17 这两个复用。
虽然这个时间轮的插入,删除,检测的时间复杂度是 O(1) ,但是可以覆盖的过期时间却取决于时间轮的大小,也就时间轮中 bucket 的个数。例如,当 currentTime 为 2:32 时,这时需要添加一个延迟 16 秒执行的任务,对应的过期时间为 2:48 ,需要找到 i =18 的 bucket,显然此时没有 i = 18 的 bucket ,所以无法插入到时间轮中。那么如何解决这个问题呢?答案是层级时间轮。
层级时间轮定时器
基本原理
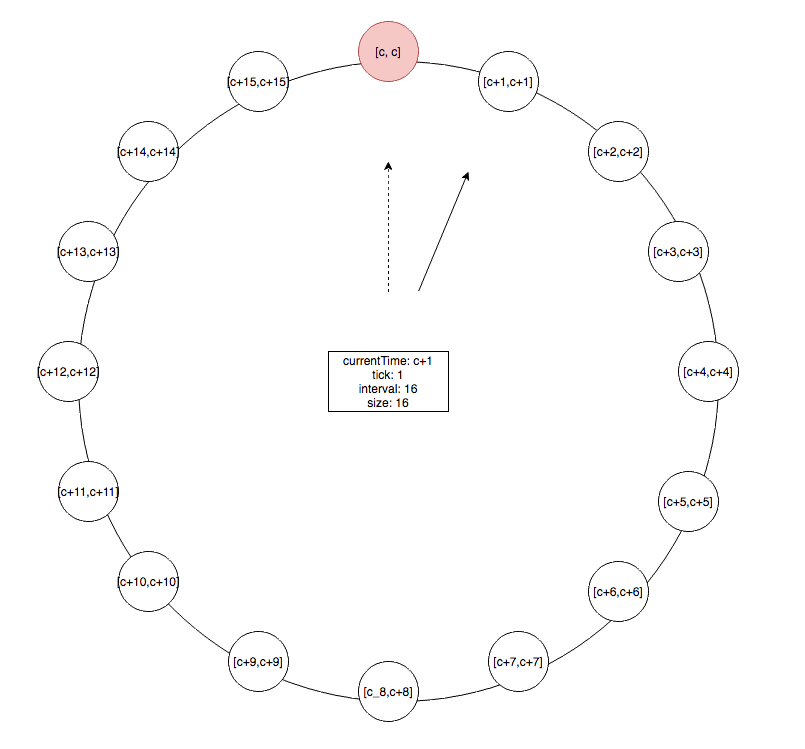
首先看第一级时间轮的结构,与普通的时间轮基本一样。假设当前时间为 c ,每次走的时间间隔为 1,每个 bucket 表示的时间区间如上图所示,整层时间轮表示的时间间隔为 1*16 = 16,即每次走的时间间隔乘时间轮大小。
那么如何添加超出了其所能表示的时间间隔的任务呢?比如我们要创建延迟 16 的任务,即这个任务在落在这层时间轮 [c+16,c+16] 的bucket上,但是此时这个 bucket 不存在,那么怎么办呢?我们新建一个更高级的时间轮。
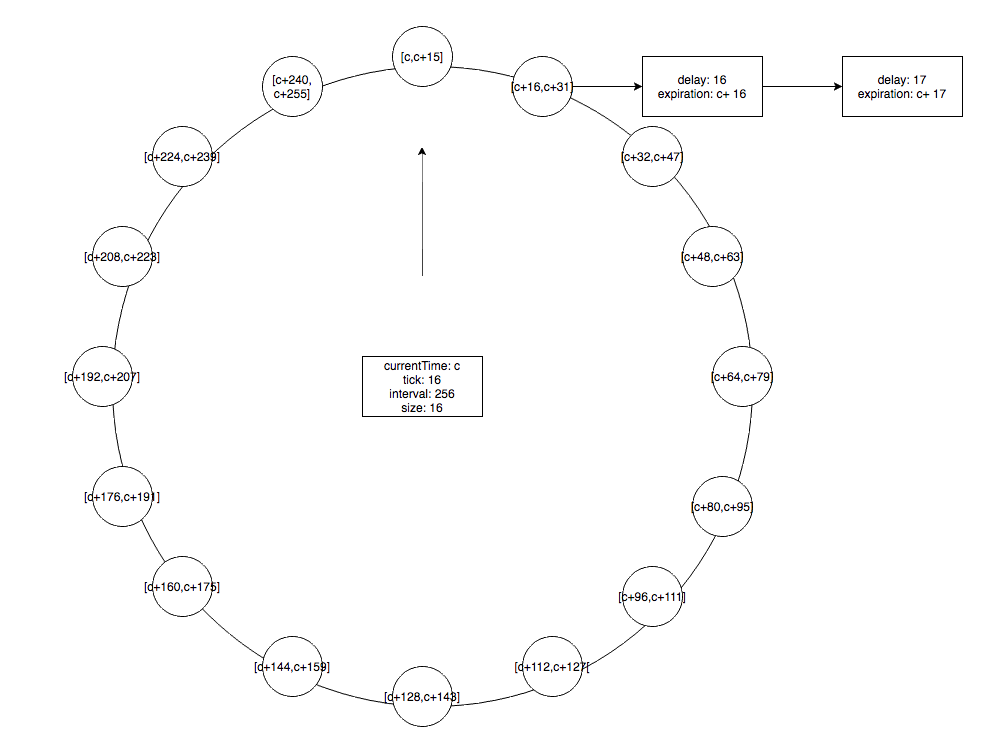
新建的时间轮每个 bucket 表示的时间间隔是上一级时间轮总共能表示的时间间隔,例如上图的时间轮中的 [c,c+15] 这个 bucket 就表示了整个上一级时间轮。在当前时刻 c 创建延迟 16 和延迟 17 的任务,就会把这两个个任务加到 [c+16,c+31] 的bucket中,多个任务会由一个链表保存。这样就能满足 [c, c+255] 的延迟间隔的需求,如果超出这个范围的任务则又会新建时间轮,时间轮的层级越高,其能容纳的时间间隔范围也就越大,只要内存足够,理论上是可以容纳无限的时间间隔的。
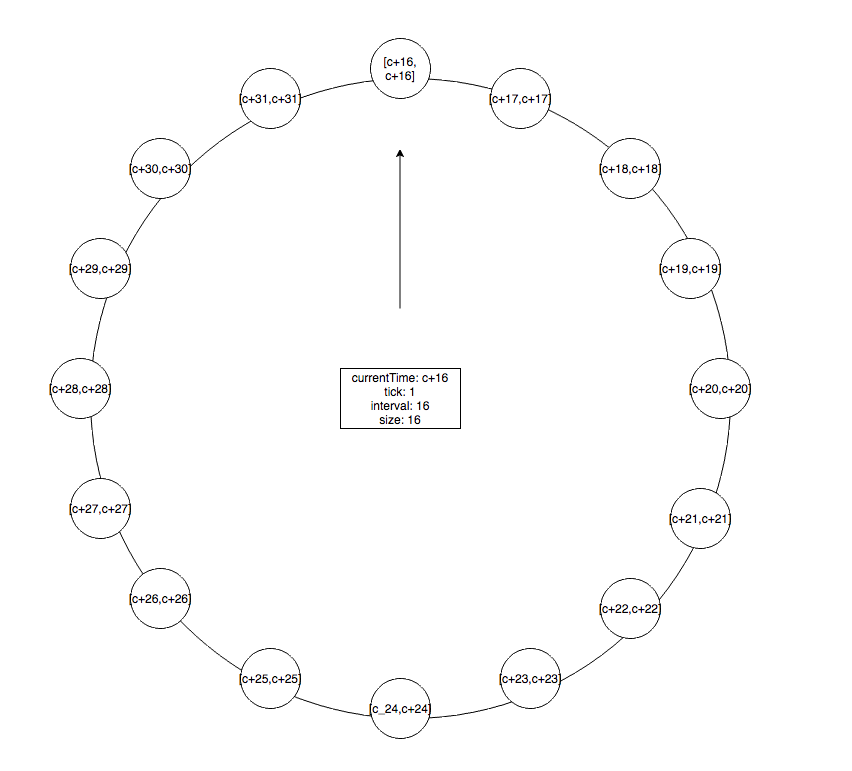
层级时间轮和普通时间轮一样也会复用已经过期的 bucket ,每个 bucket 表示的时间间隔不变,但其表示的过期时间范围,会随着时间的推移,指针的驱动不断变化。
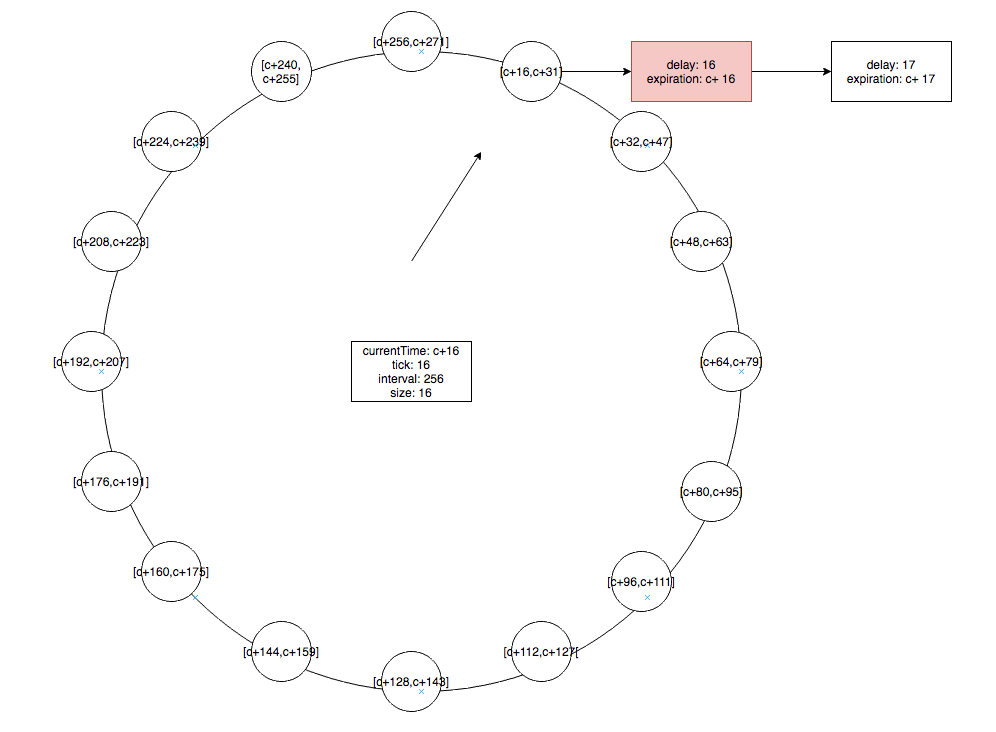
当第一级时间轮走完一圈时,第二级时间轮会指向下一个 bucket ,例如当 currentTime 为 c+16 时,指针指向 c+16 的bucket,此时会将 bucket 中的任务一一取出,过期的任务会执行,未过期的任务,会放入更低一级的时间轮。比如 delay 为 16 的任务在 c+16 时被执行, c+17 的任务则会被重新加到第一级时间轮。
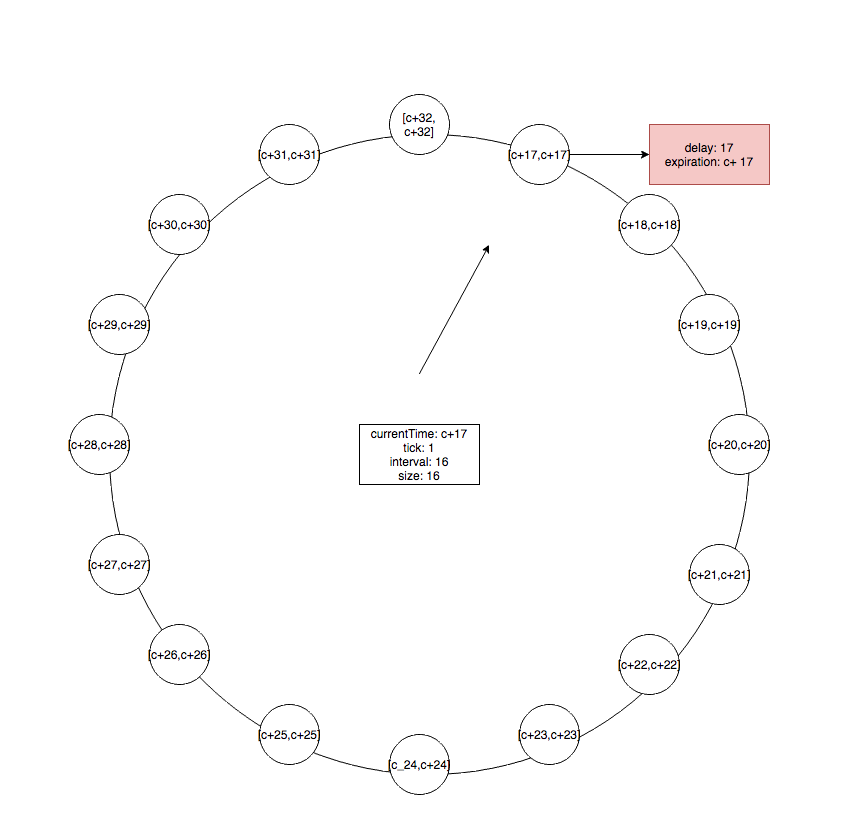
当第一级时间轮走到 c+17 时,那么 deley 为 17 的任务会取出执行。因为层级越高,每个 bucket 表示的时间间隔越大,时间精度就越低,将高层级的任务重新插入到低层级的时间轮上可以保证每个任务的时间精度为最低级时间轮 bucket 的时间间隔。
代码实现
这里主要参考 kafka 时间轮的实现,使用 Go 实现了一个时间轮定时器 timingwheel。
首先来看下时间轮的基本结构
|
|
新建一个时间轮
|
|
接下来是比较关键的部分,如何把任务添加到时间轮上
|
|
|
|
|
|
add 函数接收的是一个 TimerTask 类型作为参数,TimerTask 包含任务过期时间 expiration 和执行任务的 Do 方法。这里对于 expiration 可能处于的三个区间做了不同的处理。
expiration在c+tick之前,说明这个任务已经过期了,所以不会加到时间轮中。expirtation在[c+tick, c+inteval)里,说明任务在时间轮所能容纳的时间间隔范围内。那么根据过期时间计算出其在时间轮中的位置,将任务加到对应位置的双向链表中,同时会更新bucket的过期时间。这里要注意的是重复添加属于同一个bucket的任务时,bucket只会添加到延迟队列一次,例如按照前面的例子,在二级时间轮中加入过期时间为c+16和c+17的任务,那么首先会对过期时间按tick对齐得到bucket的过期时间为c+16,setExpiration方法会首先判断bucket的过期时间是否与要修改的值一样,如果一样则返回false,相同则返回true。setExpiration返回true才会把bucket加入到延迟队列。expiration在c+interval之后,说明这个任务的过期时间已经超出了当前时间轮所能容纳的时间间隔,那么需要将其加到更高一级的时间轮上。
接下来是如果驱动时间轮的部分,因为时间轮上 bucket 的个数不会太多,海量的定时任务会分散到不同的 bucket 里。所以还是使用优先队列实现的延迟队列来驱动时间轮,因为不是每个 bucket 上都有过期任务,使用延迟队列也避免了经过每个 tick 都需要检测相应 bucket 的开销。这里延迟队列用的是 kubernetes/client-go 中的延迟队列来驱动时间轮,client-go 中延迟队列的实现是一个阻塞队列加堆的实现。
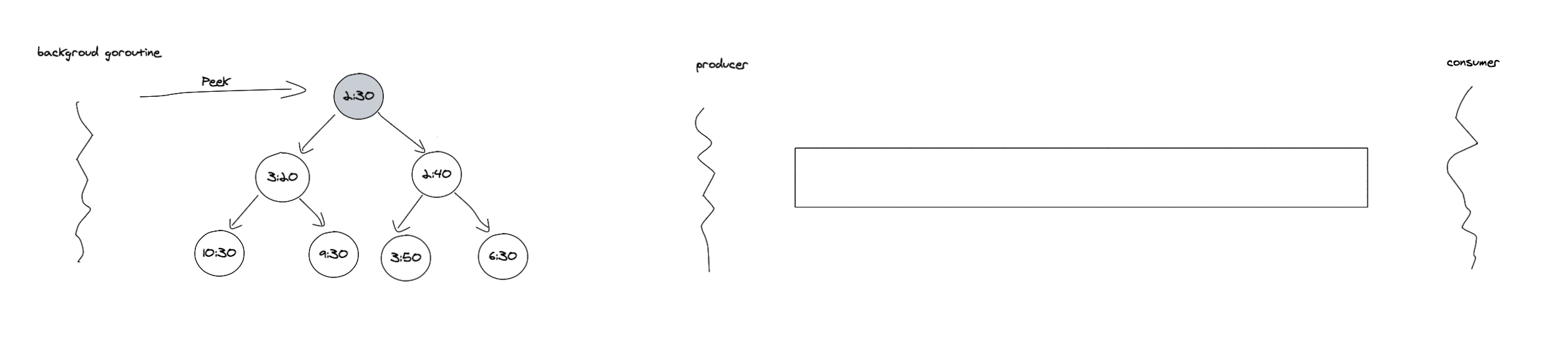
加入的定时任务会首先加入到堆中,然后有一个后台 goroutine 不断地去查询堆顶的任务是否过期,如果过期了就将其从堆里取出来放入阻塞队列中。
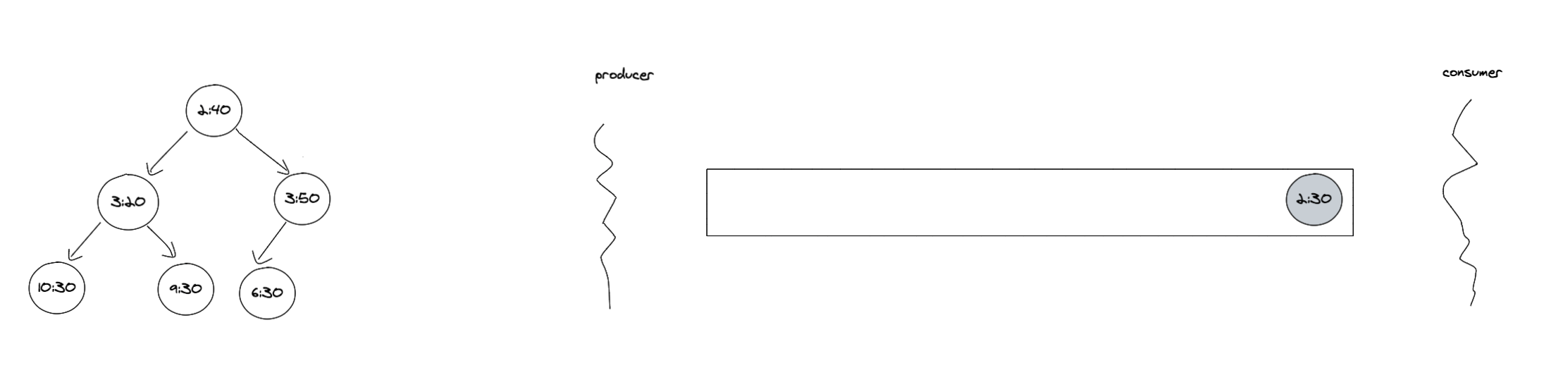
加入到阻塞队列后,消费者会从队列中取出任务,取出任务后任务处于 processing 状态,调用者需要在完成任务后调用Done方法表示任务已完成。如果不调用 Done方法是无法再将这个任务放回队列的。
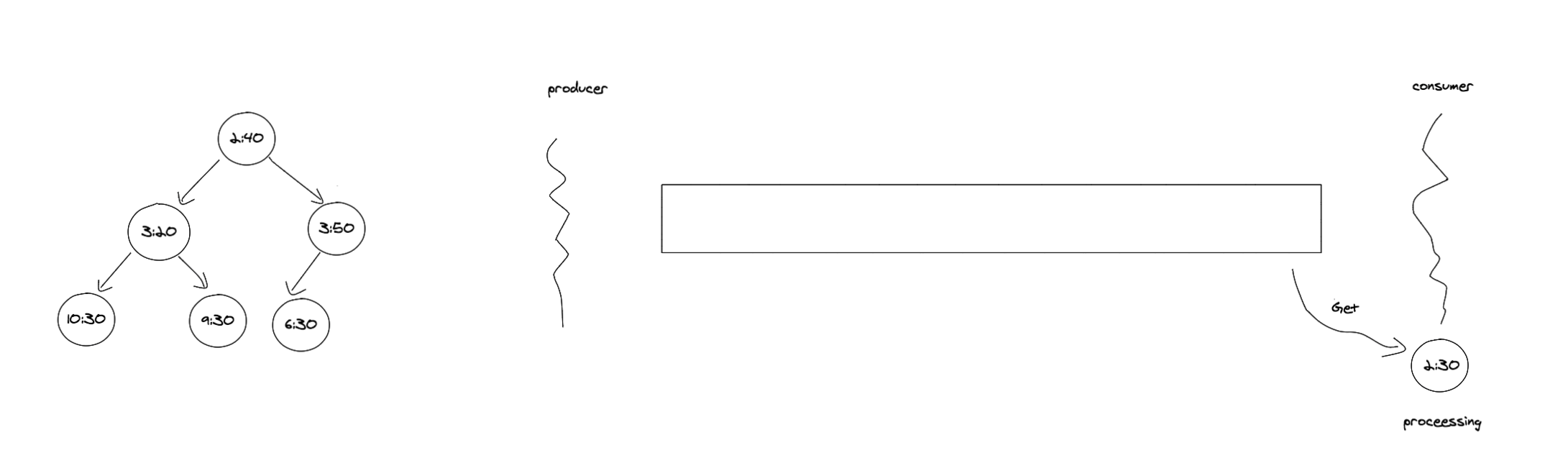
接下来看看时间轮中的任务如何定时执行。
在新建时间轮后需要调用 Start 方法,注意这个方法是阻塞的,所以在调用时需要开启一个 goroutine 来调用。
|
|
|
|
Start 方法中会不断的从延迟队列中取出已经过期的 bucket,同时更新时间轮的 currentTime 为当前 bucket 的过期时间,然后遍历 bucket 中的所有定时任务,将任务从双向链表中移除,然后再尝试加入到时间轮中,因为有些任务可能还没有过期,需要加到更低的时间轮中。如果任务已经过期了,那么就真正执行这个定时任务。
总结
Kafka 时间轮定时器的设计十分精巧,实现起来也比较简单,这次也算是通过时间轮定时器复习了一些基础的数据结构。当然这个实现可能还有些不足,比如并不是并发安全的,需要持续改进。