限流简介
通过限制服务速率来保护服务,保证尽自己最大能力服务。
限流可以针对 QPS /并发数/连接数/网络传输速率等。
固定速率限流
来看看 uber-go/ratelimit 的实现。
首先看一下最简单的限流算法实现。假设限流的最大 QPS 为 1000,那么每个请求之间的时间间隔是 1ms,每次通过当前请求的时间和上次请求的时间计算出两个请求之间的时间间隔,如果时间间隔 >1ms 则放行,如果 <1ms 那么阻塞或丢弃请求,阻塞的话可以计算出需要阻塞多久。
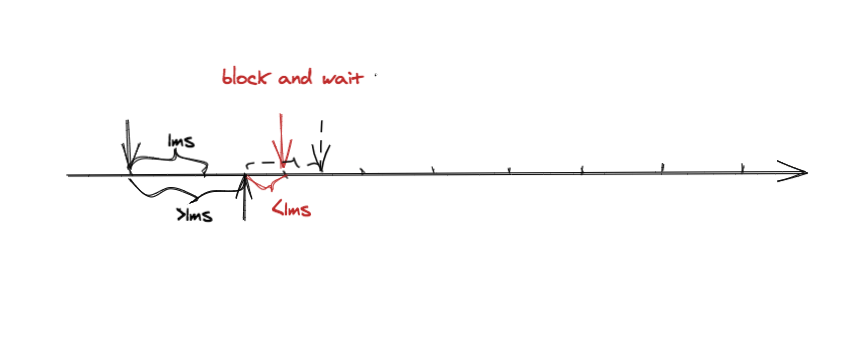
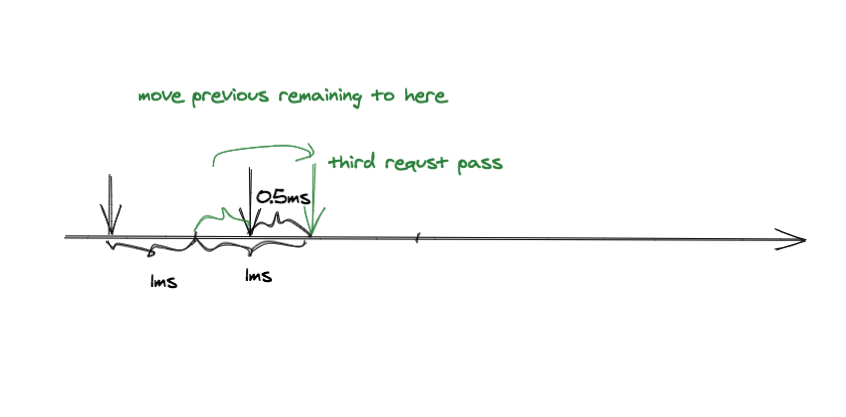
接下来看另一种情况,请求 2 在请求 1 后面 1.5ms 到达,请求 3 在请求 2 后面 0.5ms 到达。按照之前的算法请求 3 需要等待 0.5ms 才能放行,所以 3 个请求总共花了 2.5ms,原本只需要花 2ms。如果有很多这种情形的话,QPS 可能远远小于之前设定的值。那么怎么解决呢?很简单,将上一次请求剩余的时间匀过来,请求 2 和请求 1 之间有 0.5ms 的空余刚好可以挪到请求 2 和请求 3 之间。这个是不是很蓄水很像?上一次没有用完的积攒在那里,等需要的时候再使用。但是也不能无限蓄,如果蓄的量很多,那么当在某一瞬间有大量请求时,无法将之前积蓄的时间都用完,导致 QPS 超过之前设定的值,这样就达不到限流的效果,所以积蓄的时间需要有一个上限,这个上限可以理解为桶大小。
核心代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// Take blocks to ensure that the time spent between multiple
// Take calls is on average time.Second/rate.
func (t *atomicLimiter) Take() time.Time {
var (
newState state
taken bool
interval time.Duration
)
for !taken {
now := t.clock.Now()
// 获取上一次请求的状态
previousStatePointer := atomic.LoadPointer(&t.state)
oldState := (*state)(previousStatePointer)
// 根据上次请求的状态设置新的状态,这里的 sleepFor 可以理解为之前桶内还剩多少,sleepFor <= 0
newState = state{
last: now,
sleepFor: oldState.sleepFor,
}
// 首次请求直接放行
if oldState.last.IsZero() {
taken = atomic.CompareAndSwapPointer(&t.state, previousStatePointer, unsafe.Pointer(&newState))
continue
}
// sleepFor calculates how much time we should sleep based on
// the perRequest budget and how long the last request took.
// Since the request may take longer than the budget, this number
// can get negative, and is summed across requests.
// 同时实现将之前剩余的减掉,和将这次剩余的加到桶中两种操作
newState.sleepFor += t.perRequest - now.Sub(oldState.last)
// We shouldn't allow sleepFor to get too negative, since it would mean that
// a service that slowed down a lot for a short period of time would get
// a much higher RPS following that.
// maxSlack 可以理解为桶大小,可以应对一定突发流量。
if newState.sleepFor < t.maxSlack {
newState.sleepFor = t.maxSlack
}
// 有剩余可以直接放行
if newState.sleepFor > 0 {
newState.last = newState.last.Add(newState.sleepFor)
interval, newState.sleepFor = newState.sleepFor, 0
}
taken = atomic.CompareAndSwapPointer(&t.state, previousStatePointer, unsafe.Pointer(&newState))
}
//阻塞等待
t.clock.Sleep(interval)
return newState.last
}
|
传统的漏桶限流器的实现一般是一个固定大小的队列,请求来了进队列,处理请求的一端以恒定的速率从队列中取出来处理,如果队列满了,新来的请求阻塞等待或者直接丢弃。uber 的实现是根据请求间隔来的,如果没有 maxSlack 这个参数做优化的话是和传统的漏桶限流基本相同的,但是通过调整 maxSlack 这个参数可以应对一定量的突发请求,这个功能又与令牌桶有些相似。
uber-go/ratelimit 的不足
- 触发限流后只能阻塞等待,突发流量较高的情况下,容易造成请求堆积,严重的情况下可能触发 OOM ,需要调用方做超时处理。
- 无法动态调整限流速率。
uber-go/ratelimit 使用场景
- 严格限定请求速率的场景,比如 API 调用速率限制。
golang.org/x/time/rate 实现。
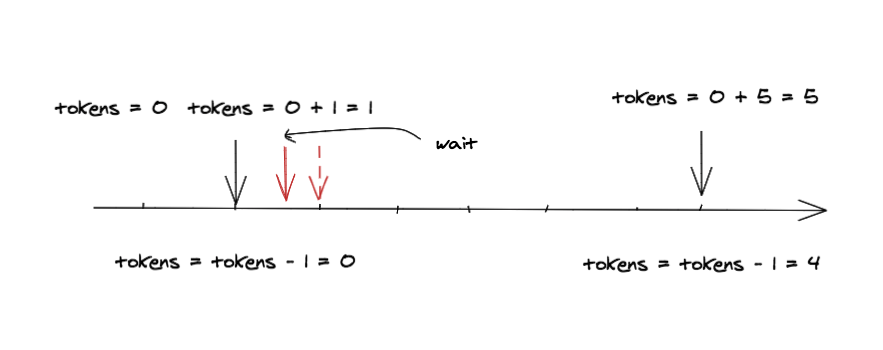
这里的实现和上面 uber 的漏桶实现有点类似,将时间和 token 相互转化,通过两次请求间的时间间隔计算出这期间加入了多少 token , 加上之前剩余的 token 再减去要消耗的 token 得到这一次还剩下的 token ,如果剩下的 token 为负数,再将 token 转化为要等待的时间。原理是比较简单的,但是实现有很多细节。
首先看一下 token 和时间相互转化,以及加入 token 这几个方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// advance calculates and returns an updated state for lim resulting from the passage of time.
// lim is not changed.
// advance requires that lim.mu is held.
// 根据当前时间计算当前桶的状态
func (lim *Limiter) advance(now time.Time) (newNow time.Time, newLast time.Time, newTokens float64) {
last := lim.last
if now.Before(last) {
last = now
}
// Avoid making delta overflow below when last is very old.
// 先计算桶内还能容纳多少,避免两个请求间间隔太长的情况下,将间隔转化为 tokens 后溢出,采取用时间间隔来判断的方法来避免溢出。
maxElapsed := lim.limit.durationFromTokens(float64(lim.burst) - lim.tokens)
elapsed := now.Sub(last)
if elapsed > maxElapsed {
elapsed = maxElapsed
}
// Calculate the new number of tokens, due to time that passed.
// 根据时间间隔计算 token, 更新桶内 token 数
delta := lim.limit.tokensFromDuration(elapsed)
tokens := lim.tokens + delta
if burst := float64(lim.burst); tokens > burst {
tokens = burst
}
return now, last, tokens
}
// durationFromTokens is a unit conversion function from the number of tokens to the duration
// of time it takes to accumulate them at a rate of limit tokens per second.
// 将 token 转换为时间
func (limit Limit) durationFromTokens(tokens float64) time.Duration {
seconds := tokens / float64(limit)
return time.Nanosecond * time.Duration(1e9*seconds)
}
// tokensFromDuration is a unit conversion function from a time duration to the number of tokens
// which could be accumulated during that duration at a rate of limit tokens per second.
// 将时间转换为 token
func (limit Limit) tokensFromDuration(d time.Duration) float64 {
// Split the integer and fractional parts ourself to minimize rounding errors.
// See golang.org/issues/34861.
// 分别对整数部分和小数部分计算,提高精度
sec := float64(d/time.Second) * float64(limit)
nsec := float64(d%time.Second) * float64(limit)
return sec + nsec/1e9
}
|
reserveN 方法是比较关键的部分,计算出当前状态下是否能通过 n 个请求,若不能通过需要等待多久。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// reserveN is a helper method for AllowN, ReserveN, and WaitN.
// maxFutureReserve specifies the maximum reservation wait duration allowed.
// reserveN returns Reservation, not *Reservation, to avoid allocation in AllowN and WaitN.
func (lim *Limiter) reserveN(now time.Time, n int, maxFutureReserve time.Duration) Reservation {
lim.mu.Lock()
// 未设置限流 直接通过
if lim.limit == Inf {
lim.mu.Unlock()
return Reservation{
ok: true,
lim: lim,
tokens: n,
timeToAct: now,
}
}
// 计算当前桶内有多少 tokens
now, last, tokens := lim.advance(now)
// Calculate the remaining number of tokens resulting from the request.
// 减去需要消耗的 tokens
tokens -= float64(n)
// Calculate the wait duration
var waitDuration time.Duration
// tokens 不够,计算要等待的时间
if tokens < 0 {
waitDuration = lim.limit.durationFromTokens(-tokens)
}
// Decide result
// 请求量没有超过桶大小 并且等待时间小于等于最大等待时间则可以放行
ok := n <= lim.burst && waitDuration <= maxFutureReserve
// Prepare reservation
// 更新 Reservation
r := Reservation{
ok: ok,
lim: lim,
limit: lim.limit,
}
if ok {
r.tokens = n
r.timeToAct = now.Add(waitDuration)
}
// Update state
// 更新令牌桶状态
if ok {
lim.last = now
lim.tokens = tokens
lim.lastEvent = r.timeToAct
} else {
lim.last = last
}
lim.mu.Unlock()
return r
}
|
限流使用的是 Wait 方法和 Allow 方法,这两个方法是 AllowN 和 WaitN 的封装,最后都是通过调用 reserveN 实现的。区别在于 Wait 方法是阻塞,可以通过 context 控制超时,Allow 方法是非阻塞的,调用 Allow 方法只会返回是否允许通过,并且是立即返回,适合丢弃请求时使用。
与 uber 的实现相比多了一些功能,比如提供了非阻塞的限流方法,限流速率可以通过SetLimit方法动态设置。
动态限流
固定速率的限流往往要根据压测结果设定指标,比如 QPS ,响应时间,修改某个功能可能会导致原来的压测的 QPS 发生变化,需要对限流配置进行更改,对于微服务场景下的限流来说配置比较麻烦,上线一个服务也可能改变其他服务的 QPS ,如果没有及时修改限流的配置,会导致一些令人头疼的问题。所以需要一种根据服务质量动态限流的方法。根据服务对 CPU,负载,响应时间的敏感程度,可以分别根据 CPU 使用率,负载大小,响应时间来进行动态限流。这里实现一种根据 CPU 使用率的动态限流策略,无需配置任何参数。
选用 google 的令牌桶作为限流的基础,因为 google 限流器可以动态设置限流速率,所以我们可以根据 CPU 使用率,在途请求数等指标来动态修改限流速率。
先看下动态限流器的基本结构
1
2
3
4
5
6
7
8
9
|
type DynamicRateLimiter struct {
limiter *rate.Limiter
curRate int //当前速率
inflight int //当前在途请求数
lastInfligt int //上个时间窗口的在途请求数
requests int //当前时间窗口请求总数 用来判断是否是空闲情况
fromOverload bool //是否已经经历了过载
mu sync.Mutex
}
|
构造限流器
1
2
3
4
5
6
|
func NewDynamicRateLimiter() *DynamicRateLimiter {
// 初始速率为 100QPS 桶大小为 10 初始可以通过的最大 QPS 为 110QPS, 之后根据服务状态动态调整
drl := &DynamicRateLimiter{curRate: 100, limiter: rate.NewLimiter(rate.Every(1/10.0*1000*time.Millisecond), 10)}
go drl.watch()
return drl
}
|
指标收集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//Allow 方法在请求进来时调用,统计在途请求数,总请求数
func (d *DynamicRateLimiter) Allow() bool {
d.mu.Lock()
defer d.mu.Unlock()
d.inflight++
d.requests++
return d.limiter.Allow()
}
//Done 方法在请求完成后调用,将在途请求数减去
func (d *DynamicRateLimiter) Done() {
d.mu.Lock()
d.inflight--
d.mu.Unlock()
}
|
状态更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
func (d *DynamicRateLimiter) watch() {
for {
//收集 CPU 使用率指标
percent, _ := cpu.Percent(0, false)
d.mu.Lock()
// CPU 使用率小于 80%, 认为没有过载
if percent[0] < 80 {
// 根据请求数判断空闲状态,防止在空闲状态下请求速率一直增加
// 在途请求数减少的情况说明服务还有空闲的能力可以进行服务
// 即使服务状态一直好也不能一直增加,避免溢出
if d.requests > 0 && (d.inflight == 0 || d.lastInfligt >= d.inflight) && d.curRate < 10000 {
if !d.fromOverload { // 没有经历过过载 慢启动 指数增长
d.curRate *= 2
} else { // 经历过载以后 可能只是在阈值下面一点点,此时应缓慢增加,防止增加超出太多,引起服务崩溃
d.curRate += int(0.2 * float64(d.curRate))
}
}
} else {
// CPU 使用率超过 80% 并且在途请求数增多,说明系统的处理能力已经达到了瓶颈,有很多阻塞的请求,此时缓慢减少,并设置过载标识
if d.lastInfligt < d.inflight {
d.curRate -= int(0.2 * float64(d.curRate))
d.fromOverload = true
}
}
// 监控统计
limitGauge.Set(float64(d.curRate))
cpuUsageGauge.Set(percent[0])
// 更新状态
d.lastInfligt = d.inflight
d.limiter.SetLimit(rate.Every(time.Duration(1/float64(d.curRate)*1000) * time.Millisecond))
d.requests = 0
d.mu.Unlock()
// 每秒更新一次
time.Sleep(1 * time.Second)
}
}
|
http 服务测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// Handler
func (h *Handler) hello(c echo.Context) error {
allow := h.limiter.Allow()
defer h.limiter.Done()
if !allow {
requestCounter.WithLabelValues("429").Inc()
return c.JSON(429, nil)
}
var o TestObject
if err := c.Bind(&o); err != nil {
return err
}
fib(int(randN(30, 35)))
requestCounter.WithLabelValues("200").Inc()
return c.JSON(200, o)
}
func main() {
rand.Seed(time.Now().UnixNano())
go func() {
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":6060", nil)
}()
// Echo instance
e := echo.New()
// Middleware
e.Use(middleware.Logger())
e.Use(middleware.Recover())
h := NewHandler()
// Routes
e.POST("/", h.hello)
// Start server
e.Logger.Fatal(e.Start(":1323"))
}
|
测试效果
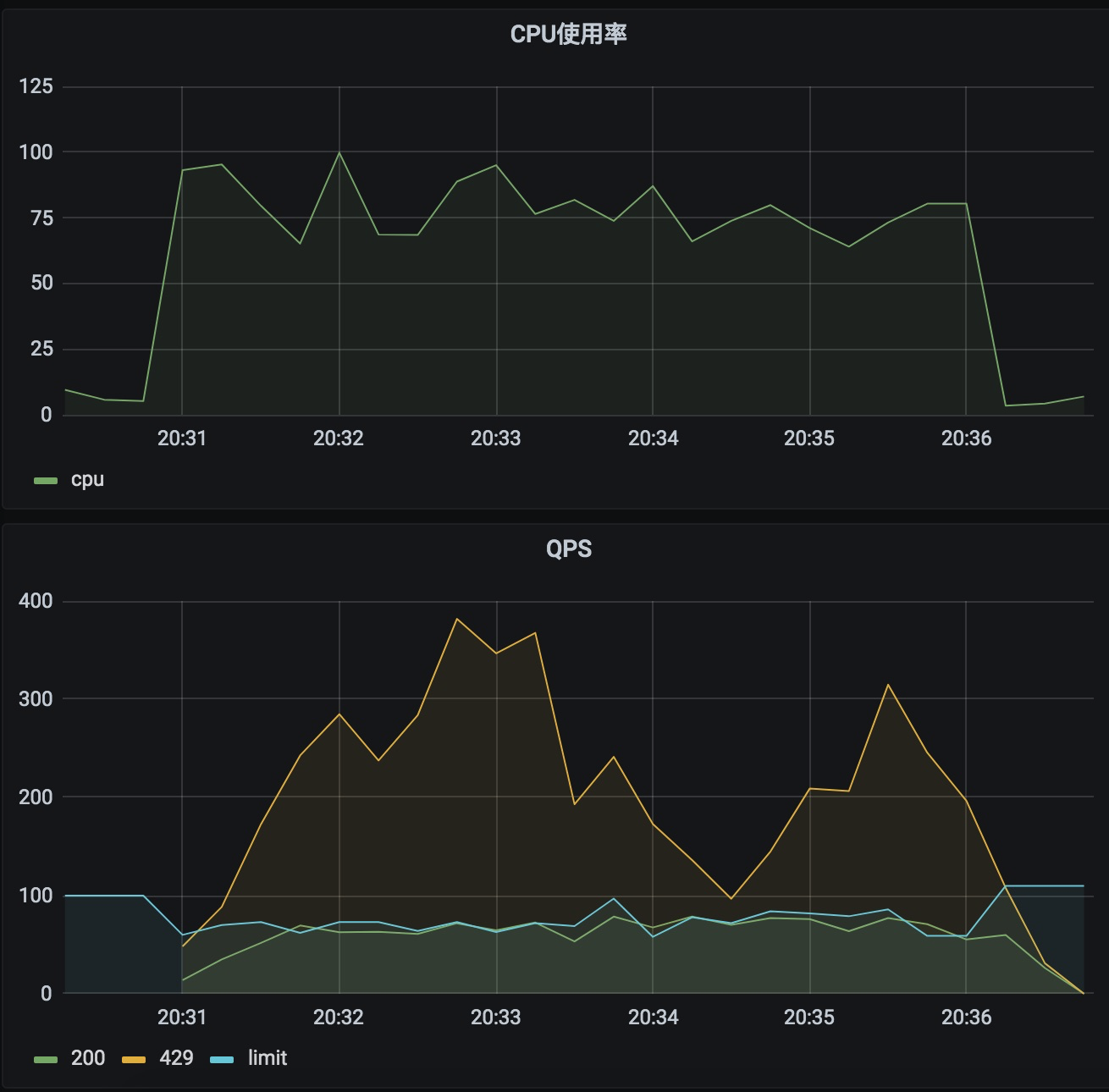
可以看到,通过动态限流保证了服务速率维持在了一个比较稳定的速率,CPU 使用率也基本保持在 80%左右。
Author
Hao
LastMod
2021-03-20
License
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可