记一次线上微服务优化过程
Contents
最近由于新的技术经理发现我们线上的某个微服务经常在高峰期 OOM, 怀疑线上的微服务存在内存泄漏问题,于是找到我来一起排查这个 OOM 问题,因为我之前一直在做平台接口开发,所以之前并没有接触到微服务这部分,对之前整个代码的实现也没有研究过,也是根据在上家公司性能优化的经验一步一步来排查问题,最终也是解决了问题,并为公司节省了很多机器,这次经历对我来说值得记录。
Golang 性能分析工具 pprof
熟悉 Golang 的应该知道分析 Golang 性能问题的大杀器 pprof,新版本的 Golang 集成了 web 界面可以方便的看到 cpu 占用,内存占用, block 住的 goroutine 数量,锁的占用等,对排查问题很有帮助。
普通的 http 服务的话就只有先引入 pprof
|
|
然后开启一个 http 服务,访问这个服务就可以看到 pprof 的信息了
|
|
具体 pprof 怎么用网上有很多教程可以参考
但是我们的这个服务是 Go-Micro 搭建的,rpc 调用用的是 grpc,grpc 要使用 pprof 的话需要在程序入口处加入如下代码
|
|
这个是设置 pprof 采样的频率,这样能够知道 groutine 阻塞在哪
通过 pprof 发现问题
在加上 pprof 监控后,我们选择了线上的一台机器进行灰度测试,刚开始的使用由于不是高峰期 pprof 测试的内存占用都在 100M 左右,没有发现特别占用内存情况。但是通过 grafana 的监控来看有很多的毛刺,而这些毛刺其实就很能够说明内存使用是有问题的。
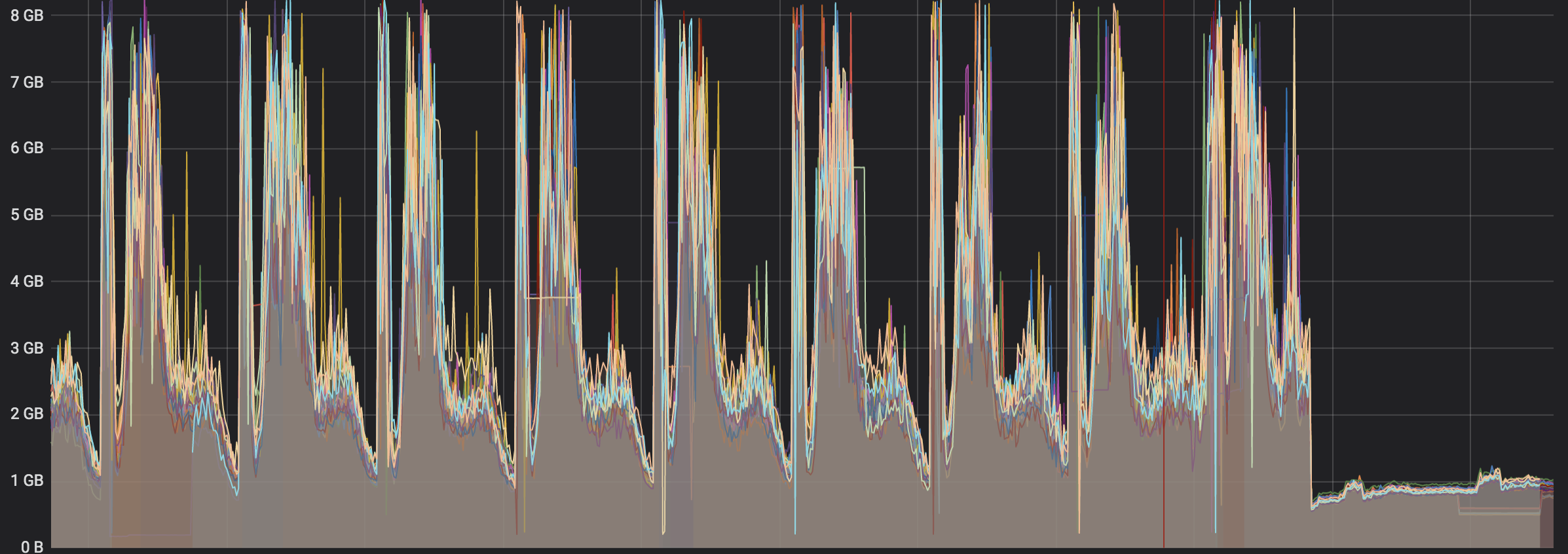
于是又在高峰期进行了 pprof 测试,终于发现了问题,原来是因为 go-micro 通过 consul 获取微服务节点信息的解码过程非常消耗内存。
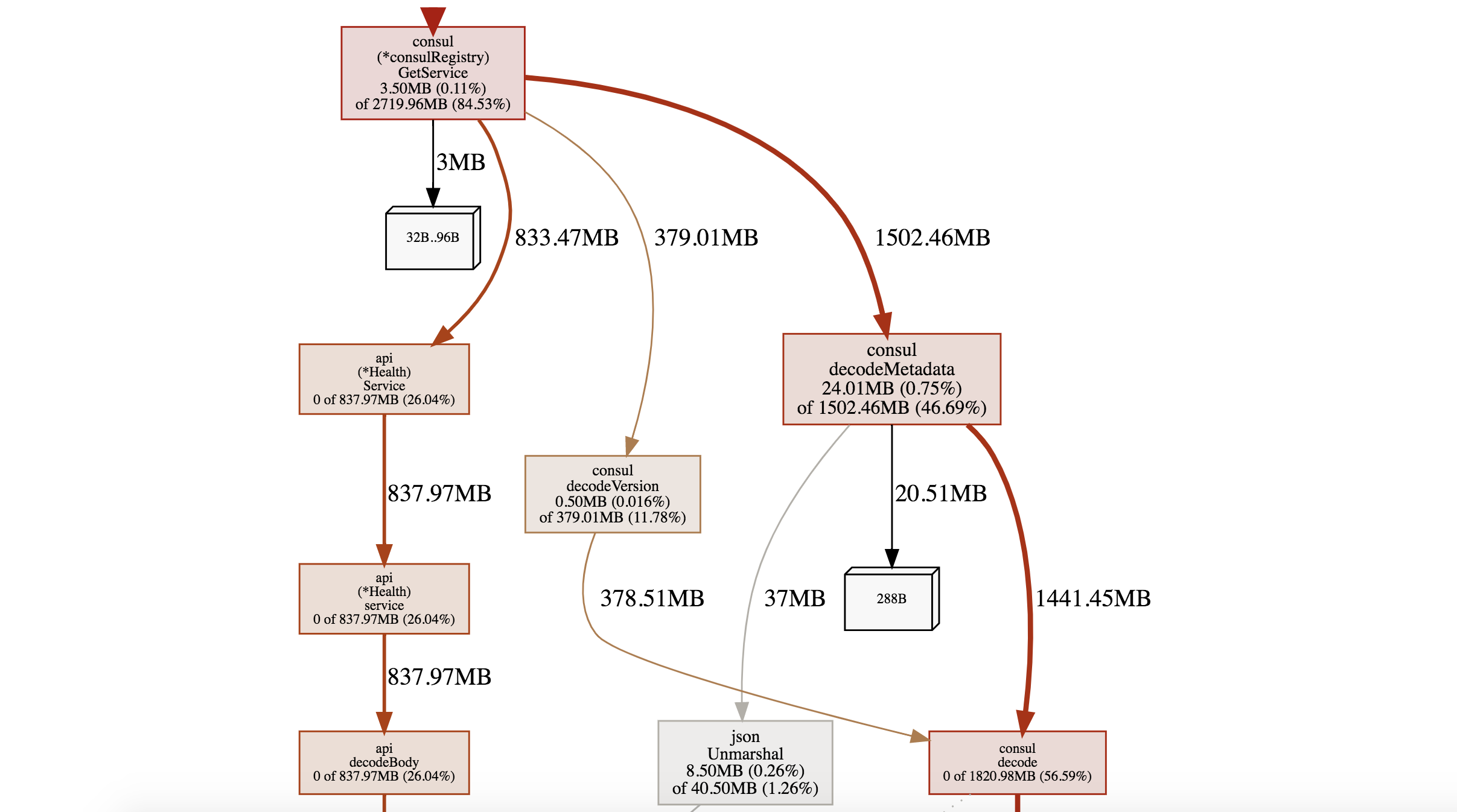
根据 ppof 提供的调用链追踪到 go-micro 源码
我们使用的微服务框架是 go-micro 1.1.0 版本。
我们通过 rpc 调用方法跳到 grpcClient 的 Call 函数,go-micro 在这里对 grpc 进行了一些封装,包括服务发现,grpc 连接池,rpc 失败重试等等,提供了很多功能,也隐藏了很多细节。
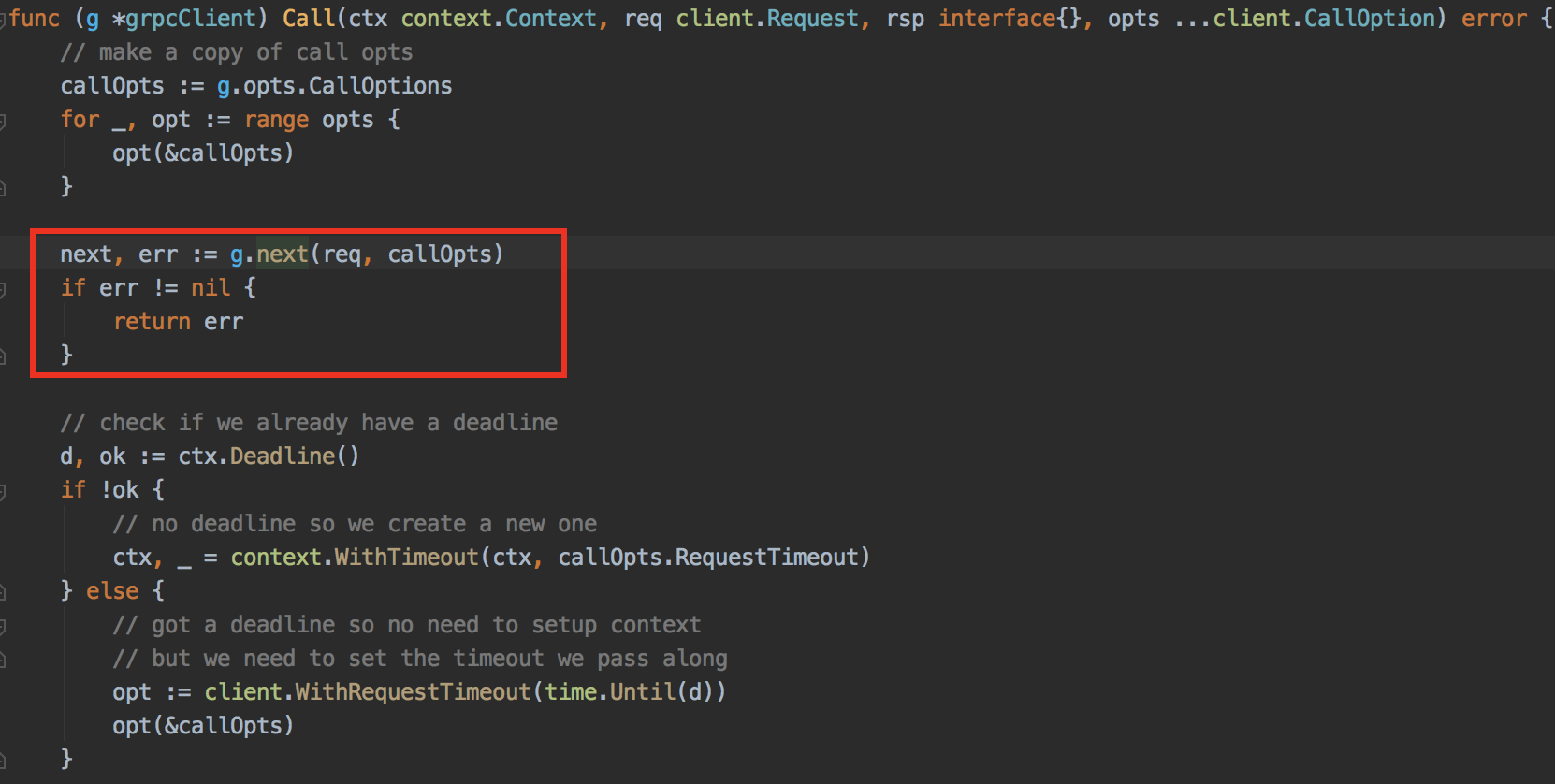
方框中 g.next() 的部分就是获取微服务节点方法,节点的选取跟 selector 的实现有关,go-micro 提供了两种 selector,一个是随机选取,另一个是轮询,我们使用的是轮询的方式。我们在这里打印了获取节点信息的耗时发现耗时会周期性的超过 10s, 甚至长的时候达到 30s, 注意是 s 不是 ms,这么长的耗时,在调用方应该已经超时了,但是我们现在并没有超时的传递机制,上游超时了不会传递给下游,所以情况就是上游服务一直重试,而下游服务确一直卡在这个地方。另外一个更加恐怖的事情是,这个地方的耗时并没有记录到整个服务的调用超时时间,所以服务设置的 rpc 超时时间并不能生效,可以看到 context 中超时是在调用 g.next() 后才设置的,所以你会在日志里发现有耗时超过十几秒,但是调用确是成功的日志。
接下来通过 g.next() 跳到 registrySelector 来看服务节点信息获取的细节
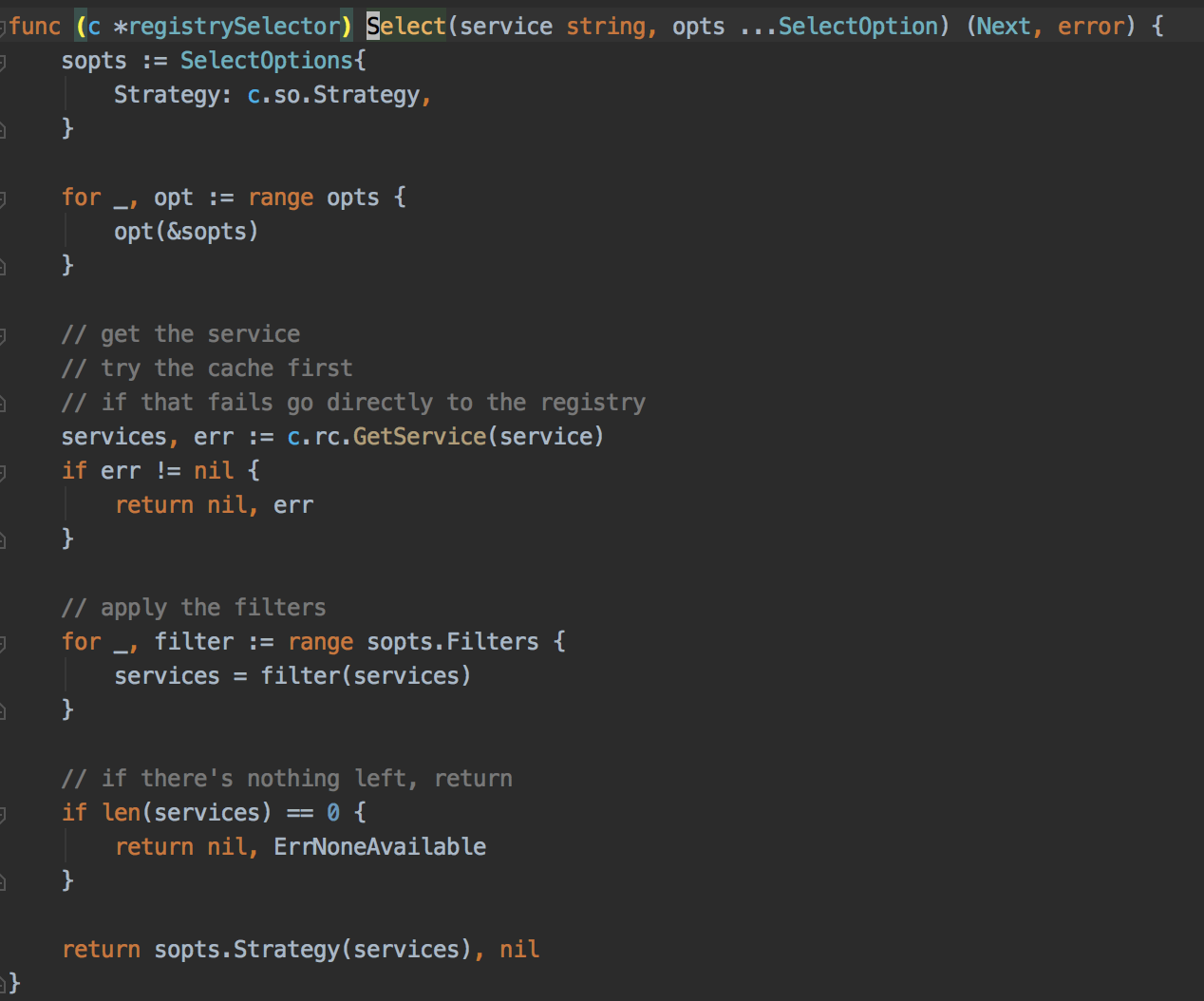
go-micro 会将节点信息用 go-rcache 管理起来,我们获取服务信息会先从 rcache 中获取,如果获取不到才会从注册中心获取,我们用的注册中心是 consul,所以会从 consul client 中获取。
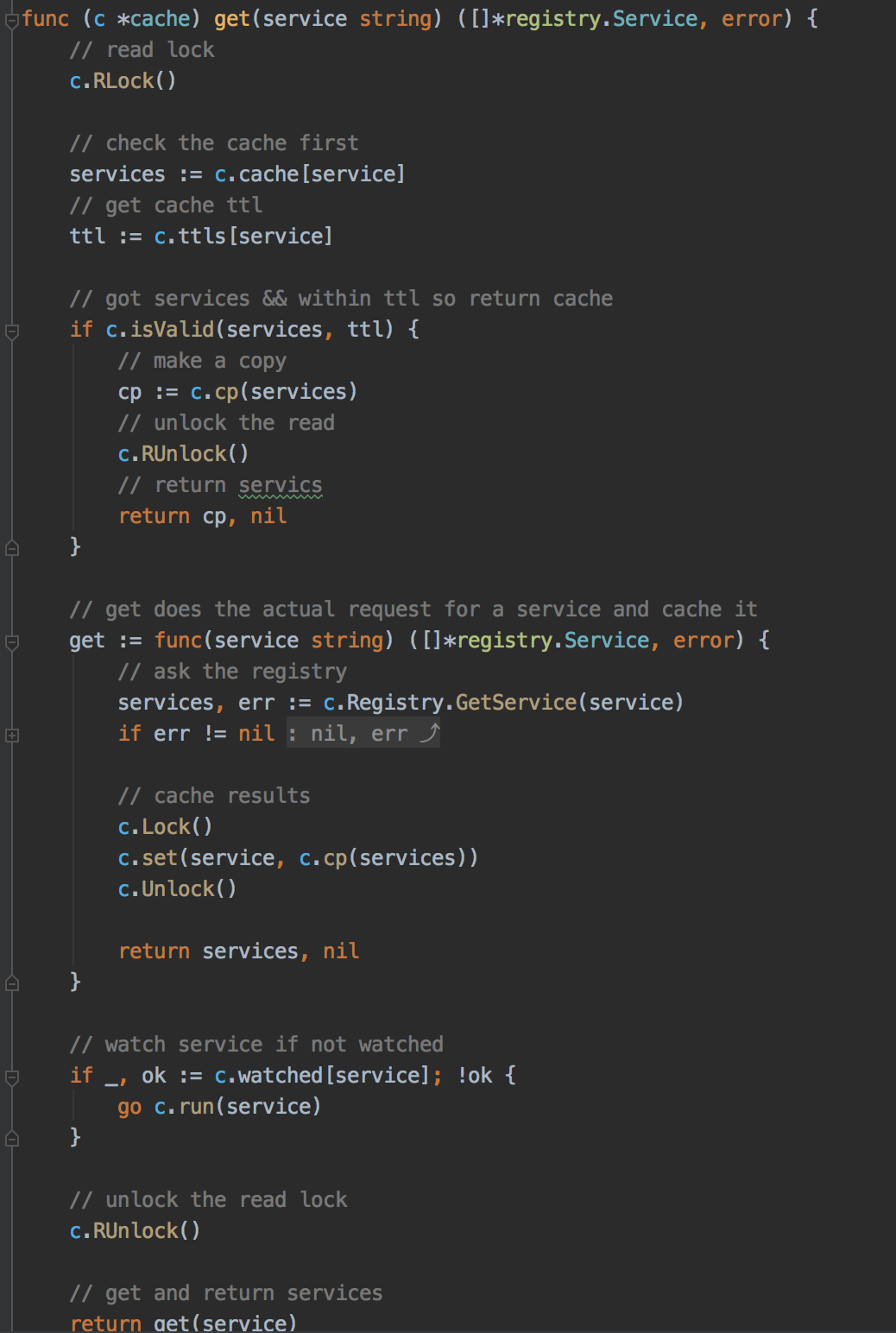
go-rcache 的实现的思路是将所有的服务节点信息按服务名存储在一个 map 里,用服务名作为 key 就能通过缓存获取这个服务下的所有主机节点,同时为每个服务维护一个缓存失效的时间,一旦缓存失效就会请求注册中心,更新服务信息。看到这里就明白了为什么我们之前在 g.next() 处打印耗时会存在周期性耗时长的现象了,很明显就是缓存失效了,重新请求注册中心导致的。但是这时又有一个疑问了,我们的注册信息是通过 consul client 获取,consul client 是和微服务部署在同一个主机上的,获取服务都是通过请求 localhost 获取的,内网请求耗时都不会超过 20ms, 通过本机获取更不可能达到恐怖的 30s 了。通过 pprof 调用图显示是对 consul 返回的节点信息进行解码导致的,然后我们跳到 consul 解码微服务信息的部分
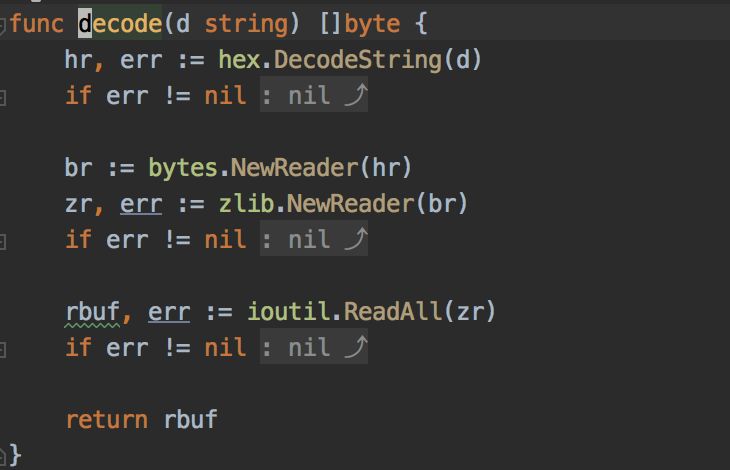
go-micro 会调用 zlib 对返回的服务信息进行解压缩,然而这个操作确实十分占用内存,github 上也有人提了这个 issue。
看到这里,问题大致就清晰了,由于高峰期并发量很高,每一次的 rpc 调用都会去走 rcache 获取服务节点逻辑,假如服务信息在 rcache 中过期,那么就会去并发从 consul 中重新获取节点信息,然后同时进行解压缩操作,内存占用就会上升,又由于没有超时传递机制,上游服务一直重试,导致积累的请求越来越多,最终用尽内存,导致 oom。
解决问题的方法
事实上 go-micro 的新版本中已经对这个地方做了一些优化,但是由于我们使用的 1.1 版本较老,新版本的 api 很多都不兼容,要升级代价太大,所以只能放弃升级寻找别的办法。
仔细想想这个问题,实际上我们并不需要每次 rpc 调用都需要去从 consul 中并发获取微服务节点的信息,只需要在服务过期时有一个 goroutine 在更新这个服务就行了。所以我们在 rcache 这个地方去 get service 的地方做了一点小小的改动。更改如下
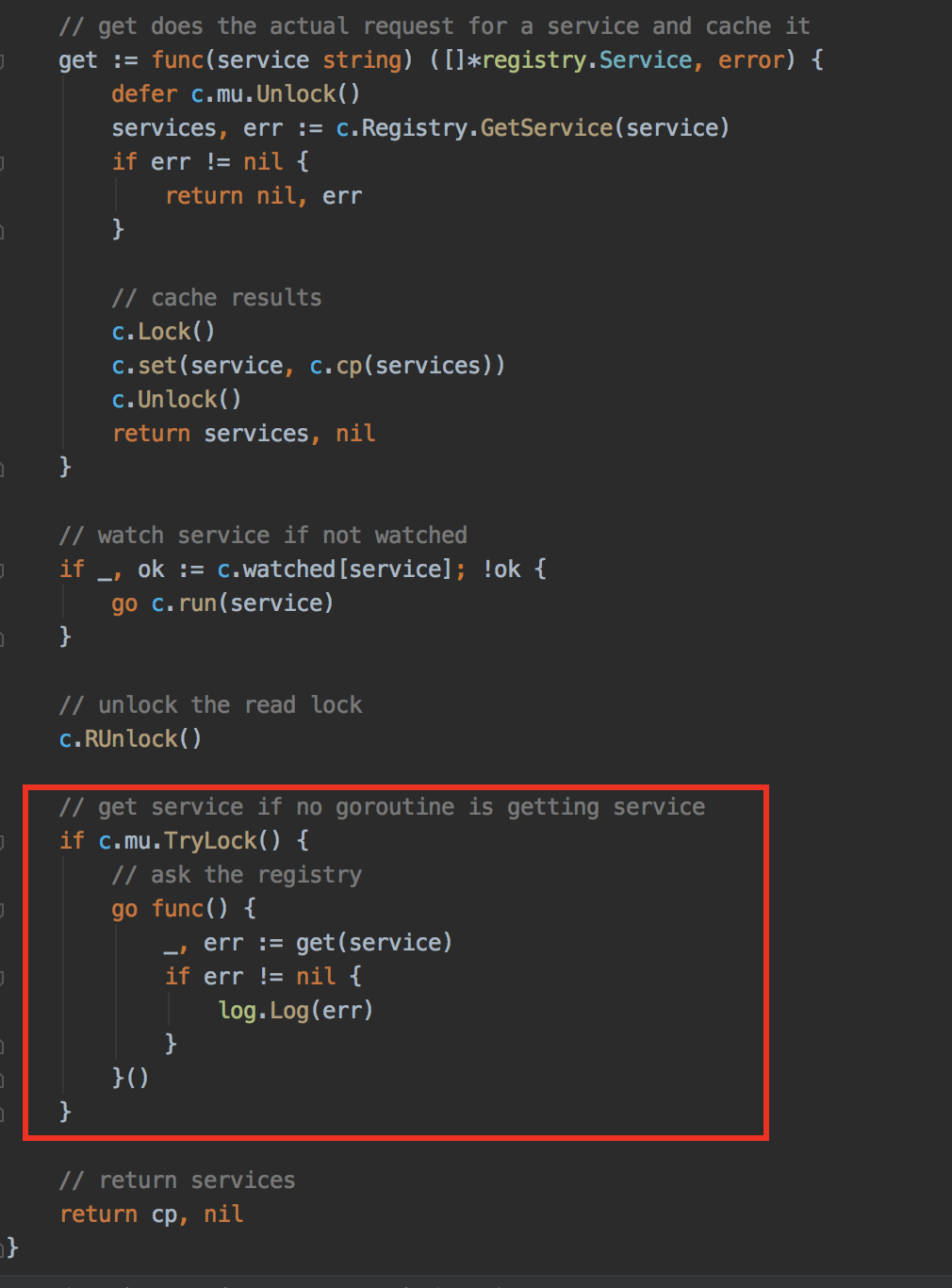
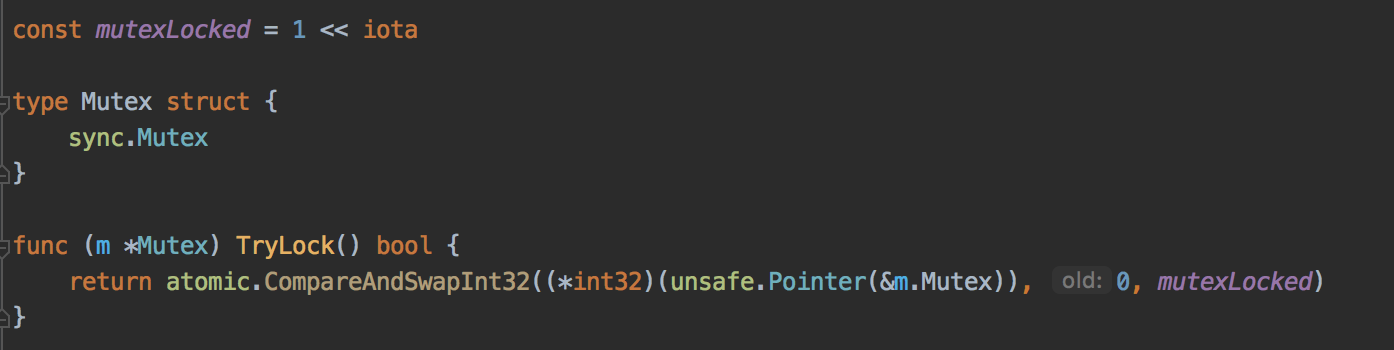
具体就是,通过 tryLock 的方式只允许一个 goroutine 在从 consul 中获取服务信息,更新服务信息,其他的调用即使此时服务过期了,也依然返回之前缓存的服务节点信息。这个想法是我们技术经理想出来的,但是他之前是搞 c++的,对 go 不太熟。我也是第一次接触 tryLock,以前都没听说过这个东西,于是在网上查了一下 tryLock, 其实就是尝试获取锁,不管有没有获取到锁都不会阻塞,而是直接进入后面的逻辑,tryLock 用 go 实现的方式有很多,我这里采取了 CAS 操作的方式,直接修改 go 原生锁的值来实现
修改 go-rcahe 后的效果
修改后首先灰度了一台机器,发现超时 10s 以上的请求已经没有,高峰期内存占用明显降低,从 grafana 的监控来看,内存占用一直比较稳定,没有凸起的毛刺。之后上线发布了这个版本,前几天看没什么问题,但是通过令牌桶的限流机制在高峰期时会产生一定量的丢包。开始也没太在意这个问题,认为有一定的丢包也正常。于是开始减机器。按照我之前的观察来看,我们灰度测试的那台机器的 QPS 峰值是在 300 左右,我认为优化后是可以达到 1000QPS,说实话 1000QPS 我都觉得有点低了,这个服务没有直接操作数据库,所有的查询走的都是内存缓存,所以 QPS 主要取决于下游的服务,从日志统计的时间来看,下游调用的耗时大部分在 20ms 以内,达到 1000QPS 只需要撑住 20 个并发请求就行,4 核 8G 的云服务器,Golang, 20 个并发应该就是小菜一碟吧。从整个服务的峰值 QPS 来看,最高大概能达到 10000QPS,所以我觉的这个服务用 10 台应该是轻轻松松就能抗住,但是我们现在用了 20 多台机器。所以我们在更新观察一段时间没问题后,直接先减了 5 台。减 5 台没有问题在我意料之中,但是后面由于改配置改错,导致有 10 台没启动,瞬间就少了 10 台,刚开始由于不是在高峰期,没有发现什么问题,然后过了一段时间就出问题,令牌桶限流开始一直丢弃请求,把那 10 台的配置改回来重启还是一直丢包。从 grafana 的监控里发现,这个服务调用的后面一个服务负载奇高,到了 100 多,然后把那台机器从注册中心直接踢下线问题才得以解决。其实以我之前的计算来看就算少了 10 台,应该还是有 10 台以上的机器在抗的,而且那时也并不是高峰期,应该是可以撑得住的。所以我怀疑是不是令牌桶的设置参数有问题,原本机器能够撑得过去,但是由于令牌桶限流设置的参数过小,导致请求被丢弃了。于是先是调大了令牌桶的参数,然后再观察。之后,我们认为模拟了这个服务后面的服务负载高的情况,问题得到了复现,然后我们打印了 rcache 获取服务部分的日志信息,发现当后面的服务负载高的时候,consul 返回的服务节点信息为空,在返回为空的情况下,我之前改的版本是会在为空的情况下并发请求 consul 一次,这个是为了服务第一次启动时没有缓存情况的特殊处理,没想到在运行过程中 consul 还会返回空的服务节点,后来在排查监控问题时才发现,运维写了一个脚本去探测服务的端口是否正常,如果超时的话就强行将服务踢下线,所以一旦后面有一台服务负载高,就会把这台机器在注册中心删除,但是由于我们的负载均衡机制是轮询,这台机器踢下线了,那么他后面的那台机器就要倒霉了,于是这个服务的下一台机器也会被踢下线,然后就这样恶性循环,最后导致这个服务的所有机器都被踢下线,于是我之前改的那个服务由于 consul 中返回的节点信息为空,依然并发去请求 consul,结果就是大量的超时,这个时候令牌桶限流生效导致大量丢包。最后我把那个初始的判断给去掉,第一次调用返回还是直接返回空,错误由上一层处理进行重试。然后观察了一周再没有出现丢包的问题,这个问题也是告一段落了。
感想
- go 的性能调试工具非常好用,非常适合定位问题做性能优化
- 开源框架会隐藏很多细节,一旦出问题排查过程十分痛苦(当然找到问题也会有些许的成就感)
- 开源框架适合初期的快速开发,一旦业务体量上来了就不好维护了,一是由于业务复杂,可能没办法跟的上框架的更新,二是开源组件众多,维护起来心智负担很重。