对于爬虫来说,首先要能够根据自身目的准确抓取自己想要的数据,其次要保证高效,对于网络数据获取这种情景而言,网络** IO 是最大的性能瓶颈,而异步是 IO 密集型任务的绝佳解决方案,特别是对于 Python **而言。
之前了解过** Python 的异步 web 框架 aiohttp**, 和异步连接数据库的框架** aiomysql**, 这次就用这两个框架来实现对豆瓣图书的异步抓取。
代理
豆瓣有反爬机制,一旦请求过于频繁会被封** ip**, 解决思路是是用代理 ip 进行访问,我们需要从网上抓取一些代理 ip, 下面是爬取代理** ip **的核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
class Proxy:
def __init__(self, loop=None):
self.loop = loop or asyncio.get_event_loop()
self.to_validate_proxy_list = []
self.valid_proxy_list = []
def close(self):
pass
async def fetch_proxy(self, url):
r = await async_get(url, self.loop)
if url == "http://www.xicidaili.com/wt/":
parser = xici_parser
elif url == "https://www.us-proxy.org/":
parser = us_proxy_parser
elif url == "https://www.kuaidaili.com/free/":
parser = kdl_parser
else:
raise ValueError
self.to_validate_proxy_list = parser(r)
async def validate_proxy(self, proxy):
r = await async_get(VALIDATE_SITE_URL, loop, proxy=proxy)
if r and r.startswith('\n\n<!DOCTYPE html>'):
self.valid_proxy_list.append(proxy)
async def work(self):
fetch_tasks = [self.fetch_proxy(url) for url in PROXY_SITE_URLS]
logging.info('Start to fetch proxy')
await asyncio.wait(fetch_tasks, loop=self.loop)
logging.info('Fetch proxy done...')
tasks = [self.validate_proxy(proxy) for proxy in self.to_validate_proxy_list]
logging.info('Start to validate proxy')
await asyncio.wait(tasks, loop=self.loop)
logging.info('validate proxy done')
logging.info('Got %s valid proxy' % len(self.valid_proxy_list))
def save(self):
if self.valid_proxy_list:
with open('proxy.txt', 'w') as f:
for i in self.valid_proxy_list:
f.write(i + '\n')
def run(self):
self.loop.run_until_complete(self.work())
self.close()
self.save()
|
上面的代码就是通过网上的一些免费代理 ip 网站抓取代理 ip, 然后进行验证是否可用,如果可用就保存下来
抓取的日志输出
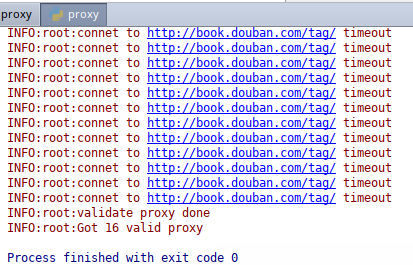
可见网上大部分免费代理 ip 都不可用,不过用来实验一下还是可以的
爬取
爬取策略是根据豆瓣的图书标签抓取** url**, 每个** url **开一个协程,通过信号量控制最多可以运行协程的数量,下面是核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
class Douban:
def __init__(self, max_tasks, loop=None):
self.proxy = fetch_proxy()
self.loop = loop or asyncio.get_event_loop()
# set the number of coroutines, which is the max working coroutines
self.max_tasks = max_tasks
self.seam = asyncio.Semaphore(self.max_tasks, loop=self.loop)
self.tags = fetch_tag()
async def fetch(self, page, tag):
tries = 0
with (await self.seam):
async with aiohttp.ClientSession() as session:
# try within 3 times and proxy list is not empty
while self.proxy and tries < 3:
# choose a proxy with random index
index = random.randint(0, len(self.proxy) - 1)
proxy = self.proxy[index].strip('\n')
try:
async with async_timeout.timeout(20):
async with session.get(
'http://book.douban.com/tag/' + tag + '?start=' + str(page * 20) + '&type=T',
headers=HEADERS, proxy=proxy) as response:
assert response.status == 200
r = await response.text()
# if response starts with <script>, it means the host uses script to avoid crawling
if r and r.startswith('<script>'):
raise ValueError
soup = BeautifulSoup(r, 'html.parser')
for i in soup.select('.subject-item'):
title = i.select_one('.info').find('a').get('title')
pub = i.select_one('.info').select_one('.pub').get_text(strip=True)
rating_nums = i.select_one('.info').select_one('.rating_nums').get_text(strip=True)
await insert(title, pub, rating_nums)
# count how many books we got
global COUNT
COUNT += 1
logging.info('Got tag: %s page: %s' % (tag, page))
break
# it should be catch exception separately
except:
tries += 1
# if tried more than three times and proxy is invalid, pop out the invalid proxy
if self.proxy and index < len(self.proxy) and tries >= 3:
self.proxy.pop(index)
# fetch failed, count the number of failed pages
else:
logging.info('fetch tag: %s page: %s failed' % (tag, page))
global FAILED_COUNT
FAILED_COUNT += 1
async def run(self):
# create database conneciton pool
await create_pool(loop=self.loop, user='root', password='123456', db='douban')
# all tasks
tasks = [self.fetch(i, tag) for i in range(3) for tag in self.tags]
# number of tasks
total = len(tasks)
logging.info('Start to fetch')
await asyncio.wait(tasks)
# close database connection pool
await close()
logging.info('Fetch done')
print('total: %s failed: %s' % (total, FAILED_COUNT))
print(COUNT)
|
异步存取数据
异步存取需要使用数据连接池,下面代码是使用aiomysql的异步连接池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import asyncio
import aiomysql
import logging
logging.basicConfig(level=logging.INFO)
async def create_pool(loop, **kw):
logging.info('create database connection pool...')
global __pool
__pool = await aiomysql.create_pool(
host = kw.get('host', 'localhost'),
port = kw.get('port', 3306),
user = kw['user'],
password = kw['password'],
db = kw['db'],
charset = kw.get('charset', 'utf8'),
loop = loop
)
async def insert(title, pub, rating_nums):
global __pool
with (await __pool) as conn:
try:
cur = await conn.cursor()
await cur.execute("INSERT INTO books (title, pub, rating_nums) VALUES ('%s', '%s', '%s')" % (title, pub, rating_nums))
await cur.close()
except BaseException as e:
print(e)
await conn.commit()
async def close():
global __pool
__pool.close()
await __pool.wait_closed()
|
结果
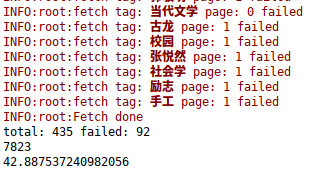
抓取每个标签的前三页,总共 435 个页面,92 页未抓取到,获取 7823 本书的数据,用时 42.887537240982056s
Author
Hao
LastMod
2018-02-15
License
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可