Bloom Filter 简介
Contents
基本概念
Bloom Filter是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点。而高效插入和查询的代价就是,
Bloom Filter是一个基于概率的数据结构:它只能告诉我们一个元素绝对不在集合内或可能在集合内。
实现原理
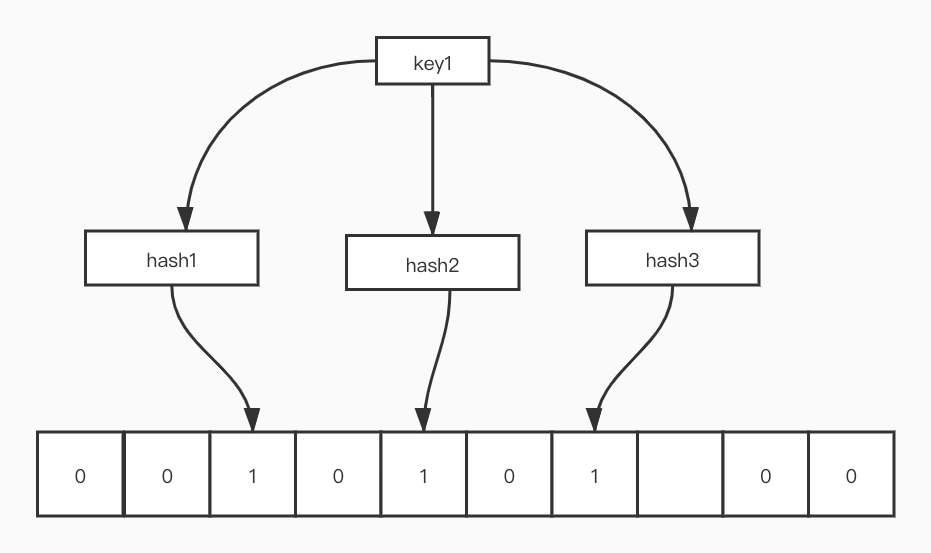
Bloom Filter的基础结构是一个比特位数组,当需要 往其中添加一个元素的时候,会使用k个哈希函数对添加的key进行哈希,得到的哈希值mod比特数组的大小,得到key在比特数组中的 k 个位置。获取的时候同样的方式查询k个位置上是否为 1,如果都为 1 那么可能存在,因为有可能其他的key已经将相应的位置置为了1,所以Bloom Filter判断key是否在其中时有一定的误判率,但是如果是查到k个位置不是每一位都是 1 的话,那么就说明 key 一定不存在。
Bloom Filter 结构示意图如下:
优点
- 空间效率高,假设有
512M内存,那么比特数组的大小是2^9 * 2^10 * 2^10 * 2^3 = 2^32=42.9 亿。如果存储的元素的个数是比特数组的1/20,那么512M内存就可以存储2 亿个元素。 - 时间效率高,插入,查询都是
O(k)常数时间复杂度。 - 散列函数相互之间没有关系,方便由硬件并行实现。
- 布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势
缺点
- 有一定的错误率。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
- 一般情况下不能从布隆过滤器中删除元素。
使用场景
- 去重,爬虫对已经爬取过的 URL 去重,推荐系统避免推荐已经推荐过的内容。
- 减少不必要的查找,
Google BigTable,Apache HBbase和Apache Cassandra使用布隆过滤器减少对不存在的行和列的查找。 解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
一些问题
哈希函数
Bloom Filter 里的哈希函数需要是彼此独立且均匀分布。同时,它们也需要尽可能的快。因此像md5, sha1这样的加密哈希函数并不适合做布隆过滤器的哈希函数,而应该使用murmur3, fnv这类的非加密哈希函数。
Bloom filter 应该设计为多大?
Bloom filter 的一个优良特性就是可以修改过滤器的错误率。一个大的过滤器会拥有比一个小的过滤器更低的错误率。
错误率会近似于 $$ (1-e^{-kn/m})^k $$ 所以你只需要先确定可能插入的数据集的容量大小 n, 然后再调整 k 和 m 来为你的应用配置过滤器。
而这带来了一个显而易见的问题:
应该使用多少个哈希函数
哈希函数越多,那么查询插入的效率会变低,但是过少又会导致错误率高,因此需要根据实际使用场景做取舍。
对于给定的 m 和 n ,m 是布隆过滤器的大小,n 是元素的个数,有一个函数可以帮我们确定最优的 k 值:
$$
(m/n)ln(2)
$$
所以可以通过以下的步骤来确定 Bloom filter 的大小:
-
确定 n 的变动范围
-
选定 m 的值
-
计算 k 的最优值
-
对于给定的* n*, m, *k *计算错误率。如果这个错误率不能接受,那么回到第二步,否则结束。
实现
做了一个简单 Golang 实现 bloom-filter。