CMU 15 445 PROJECT #3 QUERY EXECUTION
Contents
概述
第三个实验是要我们实现sequential scans, inserts, hash joins, aggregations这几个执行器。因为现在还没有实现通过SQL生成执行计划这个功能,所以执行器执行的是直接手写的执行计划。
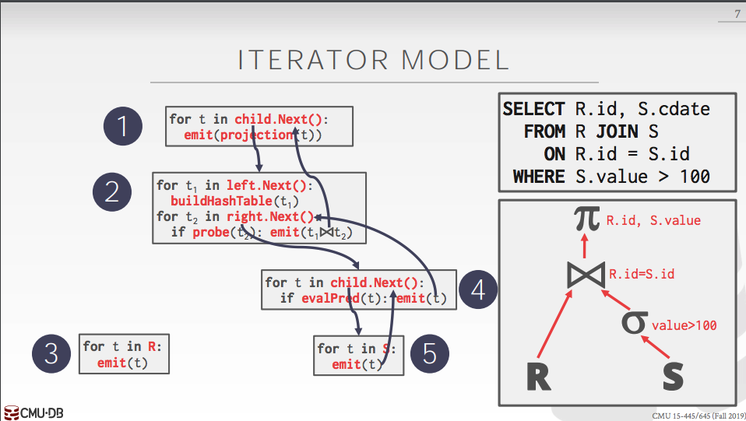
我们使用的是迭代执行模型,每个执行器都实现一个Next方法,Next方法每次会返回一个Tuple(一条数据),这个Tuple是通过param out形式传出来的,如果还存在符合条件的Tuple会一直返回true,Tuple会通过函数参数不断的传出来,如果已经没有符合条件的Tuple了就会返回false, 这一层的执行结束。上层的执行拿到下层传上来的Tuple继续执行,直到根节点执行结束,返回符合要求的Tuple,整个执行结束。
TASK #1 - CREATING A CATALOG TABLE
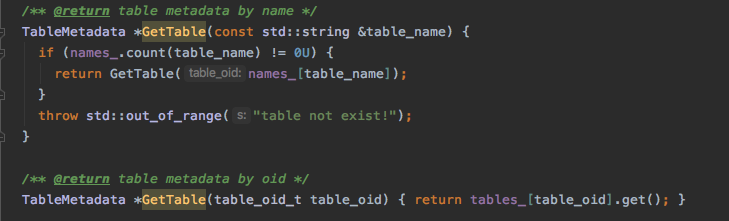
catalog用于保存一些数据库的原信息,比如有哪些表,怎么取这些表。我们要实现的是创建表的时候将表的原信息插入到catelog, 要获取某个表的是可以通过表名或者是table_oid_t(表 ID 标识)从catelog来获取表。主要实现三个函数CreateTable, GetTable(const std::string &table_name), GetTable(table_oid_t table_oid)。
CreateTable 的实现
这里主要有三点要考虑:
-
表中数据存在哪里,表中的数据由
TableHeap保存,所以首先要创建一个TableHeap。TableHeap里面维护的是一些Page, 提供插入Tuple, 获取Tuple的方法,是与底层存储交互的中间层。 -
表的元信息的创建,表的原信息由
TableMetadata这个结构来维护,主要是schema(表结构,比如这个表有几个字段,每个字段的类型是什么,长度是多少),表名,table_heap(表中的数据),t_oid(表的唯一标识)。 -
表名,表唯一标识和表元信息的绑定。
代码:

GetTable 的实现
这个实现比较简单,就是从维护绑定关系的map里通过表名或t_oid取出相应的表原信息。
代码:
TASK #2 - EXECUTORS
这部分要真正实现执行器,包括sequential scans, inserts, hash joins, aggregations,每个执行都要实现Init和Next方法,Init方法主要是初始化一些内部的状态,比如获取要扫描的表。Next方法就是根据执行计划节点返回Tuple。
执行器初始化的参数有两个,一个ExecContext, 一个PlanNode。ExecContext主要是保存了一些执行的上下文,比如当前的事务,全局的Buffer Pool Manager,LogManager等。PlanNode就是给的具体执行计划的节点,根据执行的类型的不同有相应的不同的PlanNode, 比如SeqScanPlanNode, InsertPlanNode等。PlanNode里面有ouput_schema, children两个比较重要的成员变量,output_schema主要是为了保存执行过程中间生成的表结构,children保存了子执行节点。另外有些执行的节点里可能包含一些过滤条件,这个过滤条件由predicate_维护,它的类型是AbstractExpression, 这个抽象类型是一棵表达式树,它的Eval方法会对表达式求值,求值的过程和执行计划执行的过程类似,都是先求子节点的值,然后向上执行直到根节点。
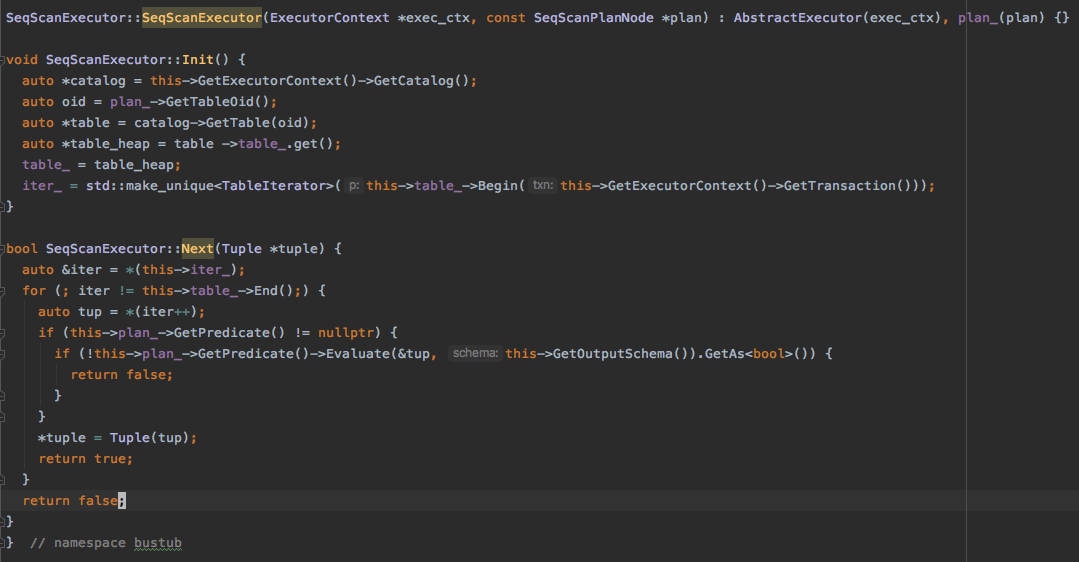
SEQUENTIAL SCANS
顺序扫描顾名思义就是从前往后顺序扫描整个表,当然有的执行计划里面会有条件,比如SELECT colA, colB FROM test WHERE colA > 500,在扫描的过程中就会判断当前的Tuple是否满足colA > 500这个条件。
Init 方法
这里主要保存两个成员
table要扫描的表。iter扫描迭代器,跟踪扫描的位置。
Next 方法
- 顺序扫描整个表
- 对
predicate求值,过滤不符合条件的Tuple
代码:
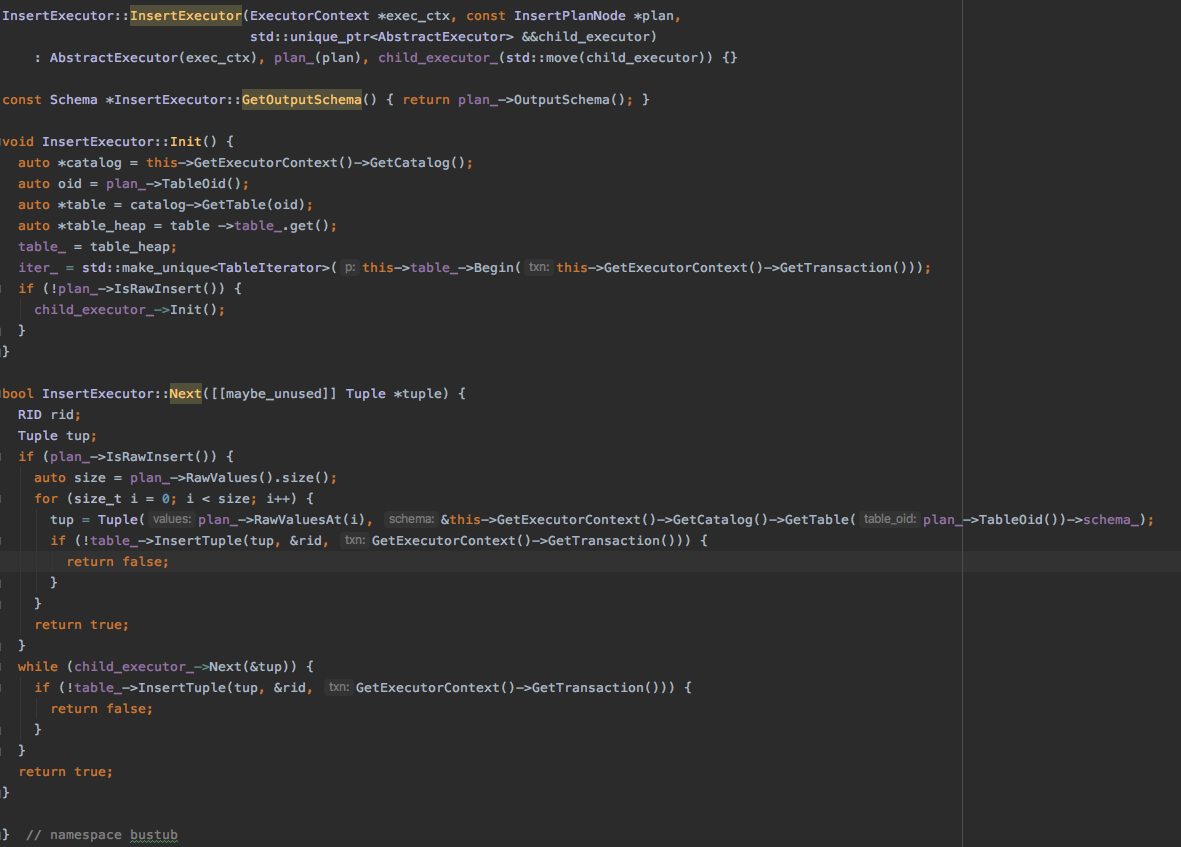
INSERT
插入执行分为两种,一种是直接插入给定的值(RawInsert),一种是插入从其他执行节点生成的值。
Init 方法
大部分和SeqScan相同,唯一不同的是如果不是RawInsert,要对子执行器进行初始化
Next 方法
分为两种,一种是RawInsert, 一种是通过获取子执行器生成的值进行插入。
代码:
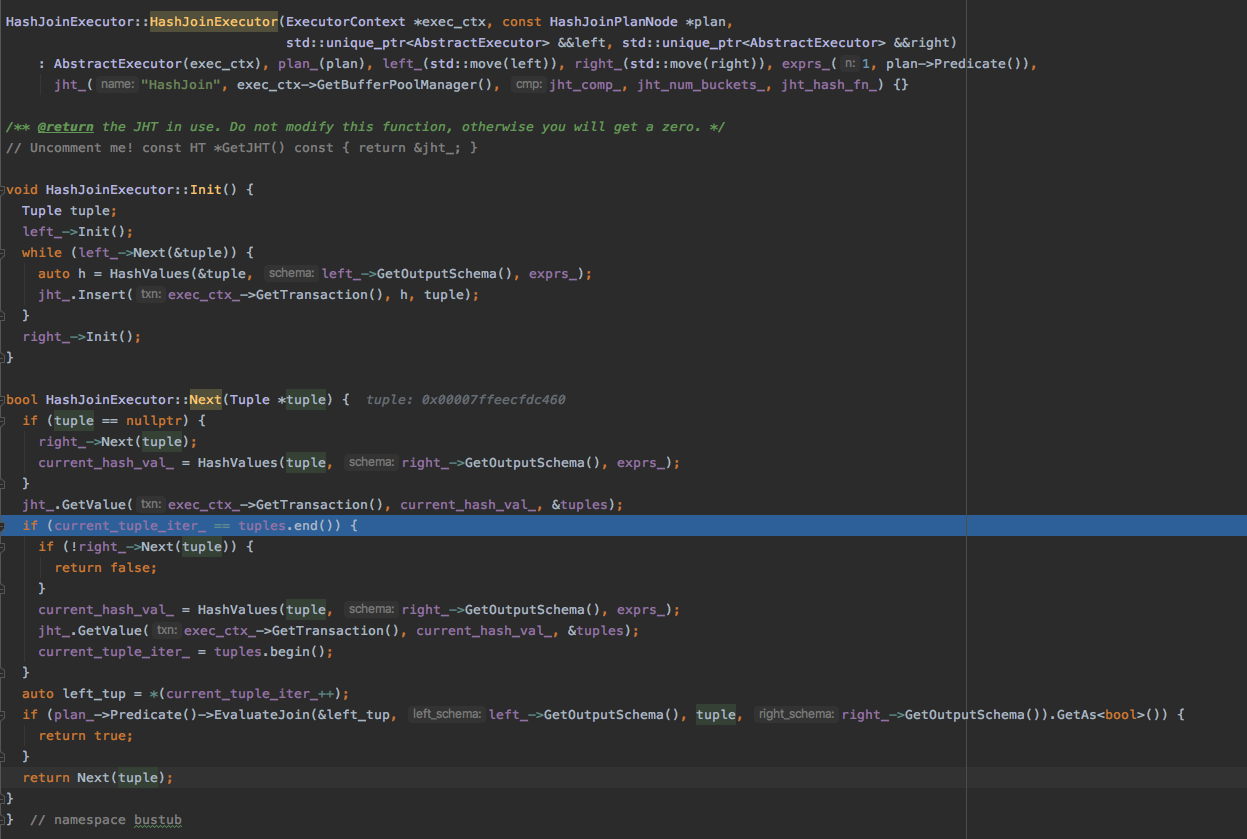
HASH JOIN
把两个子执行器的执行结果根据关联条件结合在一起。实验已经提供了哈希表,哈希函数可以直接使用。
首先看一下要加的成员变量:

Init 方法
首先初始化左执行器,然后执行左执行器,将左执行器的结果加入到哈希表中,最后初始化由执行器。
Next 方法
-
首先执行
right_的Next方法获取右边的一个Tuple。 -
对取出的
Tuple进行哈希获取hash_val。 -
根据
hash_val去哈希表获取Tuples(这里的Tuples都是左边执行的结果)。 -
然后对从哈希表中的
Tuples逐一和当前右边的tuple进行EvalJoin, 如果满足条件则返回join后Tuple。 -
直到右边的
Next不再返回Tuple执行结束。
代码:
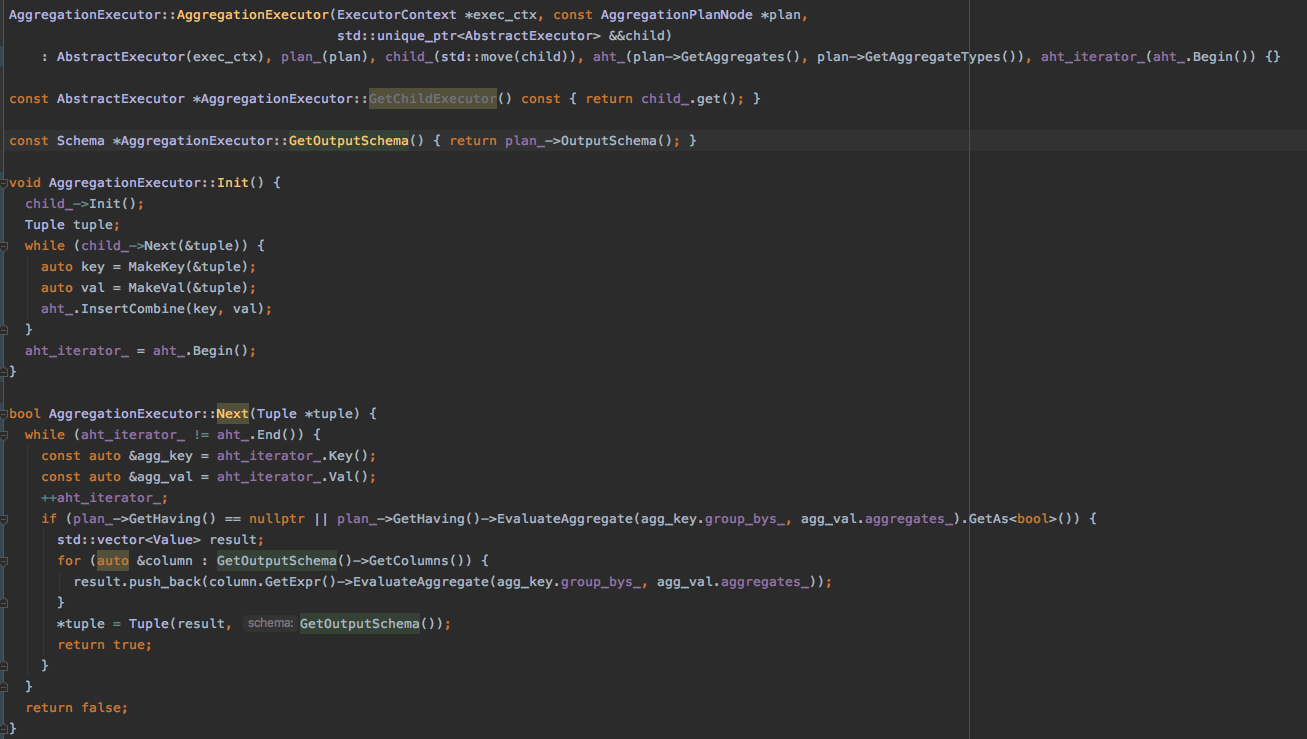
AGGREGATION
aggregation的作用将一个子执行器结果中的多个Tuple聚合成一个Tuple。
这里有两个重要的成员变量aht_(聚合使用的哈希表),aht_iterator_(哈希表迭代器),这两个实验已经提供。
Init 方法
首先初始化子执行器。
然后执行子执行器构建聚合哈希表,在构建哈希表的过程中会根据group by的key对tuple中对应的column进行聚合,生成的哈希表结构以group by keys作为哈希表的key, 以聚合后的值作为哈希表的value。
Next 方法
遍历哈希表,过滤 Having 子执行计划,将哈希表中符合条件的记录返回。
代码:
TASK #3 - LINEAR PROBE HASH TABLE RETURNS
这部分是要把HashJoin使用的哈希表换成我们之前自己实现的哈希表,由于没有提供测试没法验证正确性,这里就暂时不做了。
总结
整体来讲这个系列的实验前两个是比较容易实现的,根据提供的课程资料和代码提示以及完整的单元测试,实现起来也不是很吃力。但第三个实现还是有点难度的,我上面基本只给出了实现的思路和代码,其中有很多细节的东西要去看代码,比如这个实验里有很多抽象的类,每个抽象类如何实现我在这里没有详细的列出来,但是这些对完成实验是很重要的,还要一点是这个实验涉及了很多现代C++新特性,对于我这种日常工作不是用C++的来说很多时候需要去查相关的语法,比如智能指针移动语义,迭代器使用的坑。总之这个实验到此告一段落了,收货还是很多。