在这个实验中将获得重新设计代码以提高并行性的经验。多核机器上并行度低的普遍因素是锁争用,提高并行度经常涉及到同时修改数据结构和加锁策略以减少锁争用。这个实验就是要使用这些技巧来提高内存分配器和磁盘块缓存的并行度。
Memory allocator
程序user/kalloctest 测试 xv6 的内存分配器性能的方式:同时运行三个进程扩大和缩小它们的地址空间,触发对 kalloc 和 kfree 的频繁调用。
kalloc 和 kfree 会获取 kmem.lock。kalloctest 打印 aquire 由于获取其他 CPU 已获得的锁而循环空转的次数,这个数据在一定程度上反应了锁争用的程度。
kalloctest 锁争用的根因是 kalloc() 只有一个维护空闲内存的链表,一把全局锁保护这个链表,所以锁争用严重,要降低锁争用,就需要修改这个数据结构,最基本的想法是一个 CPU 一个空闲内存链表,每个空闲链表都有自己的锁,不同的 CPU 分配释放内存是并行的。这个方案遇到的问题是当一个 CPU 的链表是空的情况,但是其他的 CPU 的链表还有空闲内存,这种情况下,空链表的 CPU 要从有空闲内存的 CPU 偷一部分来使用,偷的过程要加锁,会产生锁争用,但是这种情况发生的频率比较低。
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU]; // 分配多个链表和锁
void
kinit()
{
for (int i = 0; i < NCPU; i++) {
char name[7];
snprintf(name, 7, "kmem%d", i);
initlock(&kmem[i].lock, name);
}
freerange(end, (void*)PHYSTOP);
}
void *
kalloc(void)
{
struct run *r;
push_off();
int cid = cpuid();
pop_off();
acquire(&kmem[cid].lock);
r = kmem[cid].freelist;
if(r)
kmem[cid].freelist = r->next;
release(&kmem[cid].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
else {
for (int i = 0; i < NCPU; i++) { // 在其它 CPU 上找空闲内存
if (i == cid) continue;
acquire(&kmem[i].lock);
r = kmem[i].freelist; // 这里只取一个节点,实现起来比较容易,尝试过窃取一半,但是发现其实不太好实现。
if (!r) {
release(&kmem[i].lock);
continue;
}
kmem[i].freelist = r->next;
release(&kmem[i].lock);
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
}
return (void*)r;
}
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int cid = cpuid();
pop_off();
acquire(&kmem[cid].lock);
r->next = kmem[cid].freelist;
kmem[cid].freelist = r;
release(&kmem[cid].lock);
}
|
Buffer cache
首先我们需要了解一下什么是磁盘块缓存(block cache),下一个文件系统的实验需要详情了解,我们先有一个基本的了解是文件在磁盘中是以块 (block) 为单位存储的,多个块一起组成一个文件。由于磁盘和内存的访问速度差别很大,所以在访问磁盘时会有一层内存缓存,block cache 就充当了这一层的角色,当具体根据哪个设备号 + 块号访问磁盘块的时候会先查缓存,缓存查不到再从磁盘加载,并设置缓存,并且有一些缓存淘汰的策略来处理缓存满了的情况。xv6 中最开始对 bcache 的实现就是一个双向链表,由一把全局的锁 bcache.lock 保护,这样当多个进程并发访问文件系统时就会造成严重的锁争用,导致文件操作的性能很差。
这里我们能不能和上面 kalloc 一样每个 CPU 分配一个 bcache 呢,然后每个 bcache 由各自的锁保护来降低锁的粒度呢?我们设想一下在上面这个方案下两个进程同时需要访问同一个文件的场景,如果两个进程都在各自的缓存中找不到,都从磁盘中加载到各自的缓存中,这样的话不同进程对文件的操作彼此都看不见,会出现数据不一致的情况,要想数据一致还是需要使用锁来进行同步。其实这里和 kalloc 的本质的区别在于 bcache 在不同的进程或 CPU 之间是完全共享的,而 kalloc 分配的内存在每个进程之间是相互独立的。所以我们需要寻找 bcache 中在进程之间相互独立的部分,我们知道对不同 block 间的修改是可以并行的,所以我们可以考虑将每个 block 分开操作,实验中给的提示方案是上个实验的分桶哈希结构来实现,将不同的 block 按块号( block no )进行哈希分到不同的桶中。
实现的思路如下:
- 首先将 bcache 均匀的分到每个哈希桶中,作为空闲的的文件系统缓存。
- 调用 bget 获取 block 时,首先按 dev + block_no 进行哈希找到它属于哪个桶,然后在这个桶中查找缓存是否存在,若存在直接返回。若缓存不存在,则在所有桶中查找一个最久没有使用且没有被引用的空闲缓存块来存放这个 block。这里查找到用来缓存的块可能是在当前块所属的桶中,也可能不是,如果不是则需要将查找到的块移动到当前块所属的桶中。
- 所有涉及到对块的操作都要按桶的粒度进行加锁解锁。
- 为了避免死锁,可以使用一阶段锁的方案,即加锁时一起加锁,并且加锁时保证每个进程加锁的顺序要一样,解锁时一起解锁,避免交替加锁解锁造成循环依赖。
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
|
// 定义桶大小和哈希函数
#define NBUFMAP_BUCKET 13
#define BUFMAP_HASH(dev, blockno) ((((dev)<<27)|(blockno))%NBUFMAP_BUCKET)
struct {
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
// struct buf head;
} bcache;
struct {
struct spinlock lock;
struct buf head;
} hashtable[NBUCKET]; // 使用哈希表结构存储磁盘块缓存
void
binit(void)
{
struct buf *b;
// 初始化锁
for (int i = 0; i < NBUCKET; i++) {
initlock(&hashtable[i].lock, "bcache.bucket");
}
// 分配缓存块到哈希表的每个桶中
int i = 0;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
int idx = i % NBUCKET;
i++;
b->next = hashtable[idx].head.next;
hashtable[idx].head.next = b;
initsleeplock(&b->lock, "buffer");
}
}
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int id = BUFMAP_HASH(dev, blockno);
acquire(&hashtable[id].lock);
// Is the block already cached?
for(b = hashtable[id].head.next; b; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&hashtable[id].lock);
acquiresleep(&b->lock);
return b;
}
}
release(&hashtable[id].lock);
uint mintick = 0;
int oldid = -1;
struct buf t;
struct buf *p = &t;
// 查找用来存放当前块的空闲缓存块,对每个桶的查找过程都只加锁,不解锁
for (int i = 0; i < NBUCKET; i++) {
acquire(&hashtable[i].lock);
for(b = hashtable[i].head.next; b; b = b->next){
if (b->refcnt == 0) {
if (oldid == -1) {
p = b;
oldid = i;
mintick = b->lastusetick;
}
if(b->lastusetick <= mintick) {
p = b;
oldid = i;
mintick = b->lastusetick;
}
}
}
}
// 没有空闲缓存块
if (oldid == -1) {
panic("bget: no buffers");
}
// 对无关的桶统一解锁
for (int i = 0; i < NBUCKET; i++) {
if (i != id && i != oldid) {
release(&hashtable[i].lock);
}
}
// 当前缓存块和要替换的缓存块不属于同一个桶,需要将替换的缓存块移动到当前桶
if (oldid != id) {
struct buf* prev = &hashtable[oldid].head;
for(b = hashtable[oldid].head.next; b; b = b->next, prev = prev->next){
if(b == p) { // 找到了替换的缓存块,从其原来的桶中删除
prev->next = prev->next->next;
break;
}
}
// 加入到新桶中
p->next = hashtable[id].head.next;
hashtable[id].head.next = p;
// 设置属性
p->dev = dev;
p->blockno = blockno;
p->valid = 0;
p->refcnt = 1;
// 统一解锁
release(&hashtable[oldid].lock);
release(&hashtable[id].lock);
// 获取 block 本身的锁
acquiresleep(&p->lock);
return p;
} else { // 在当前缓存块所属的桶中找到了空闲的缓存块,不需要移动。
// 设置属性
p->dev = dev;
p->blockno = blockno;
p->valid = 0;
p->refcnt = 1;
// 解锁
release(&hashtable[id].lock);
acquiresleep(&p->lock);
// 获取 block 本身的锁
return p;
}
panic("bget: no buffers");
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int id = BUFMAP_HASH(b->dev, b->blockno);
acquire(&hashtable[id].lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->lastusetick = ticks;
}
release(&hashtable[id].lock);
}
void
bpin(struct buf *b) {
int id = BUFMAP_HASH(b->dev, b->blockno);
acquire(&hashtable[id].lock);
b->refcnt++;
release(&hashtable[id].lock);
}
void
bunpin(struct buf *b) {
int id = BUFMAP_HASH(b->dev, b->blockno);
acquire(&hashtable[id].lock);
b->refcnt--;
release(&hashtable[id].lock);
}
|
总结
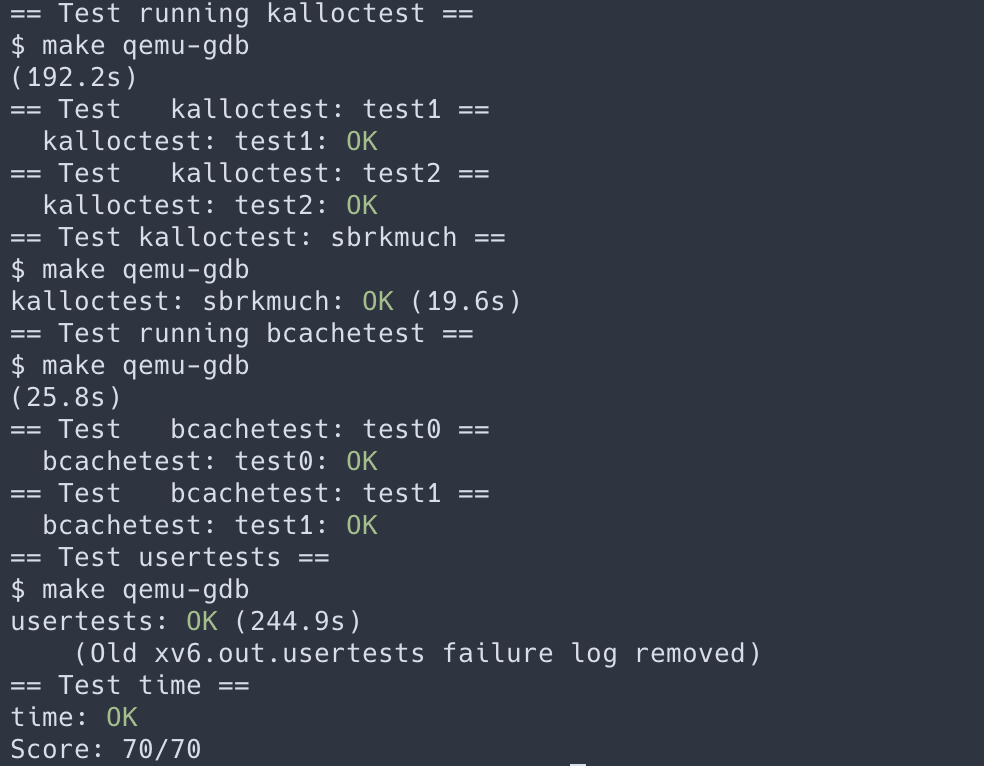
这个实验加深了对锁的使用和理解,锁争用是影响程序性能的一个重要因素,我们设计程序时首先要考虑能不能无锁实现并发访问,利用合理的数据结构,原子操作等方式避免使用锁。如果无法避免使用锁则要考虑如何降低锁的粒度,减少锁争用。在使用锁时要考虑是否会发生死锁,如何避免死锁。
Author
Hao
LastMod
2022-02-03
License
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可