了解 RabbitMQ
Contents
如果只停留在如何使用 RabbitMQ 层面,根据官方教程了解一些基本的组件比如 Channel, Exchange, Queue 这几个组件的概念以及他们之间的关系基本可以应对大部分使用场景了。但是本着学习其运行机制的心理,还是稍微深入一点,探究一下其消息发送的整个过程。
RabbitMQ 启动过程
初始化
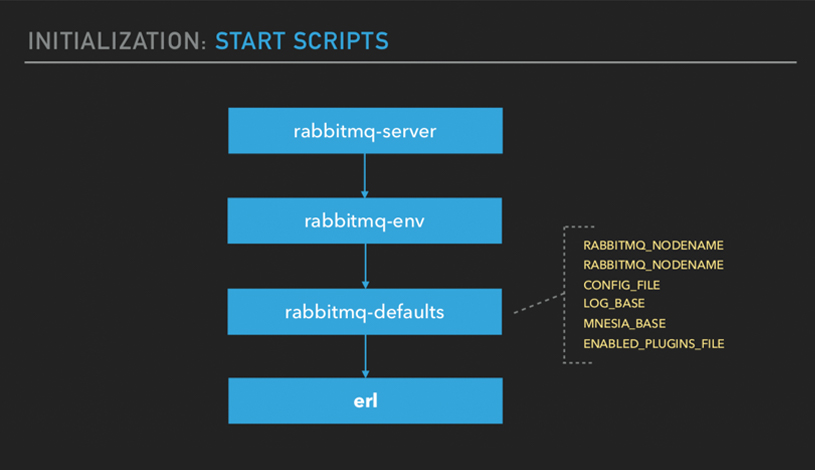
首先会执行启动脚本,然后读取环境变量,加载配置,启动 erlang node,更据 RABBITMQ_START_RABBIT 环境变量启动对应的模块,默认会启动 Rabbit:boot ()。接下来会根据配置文件更新配置,执行一些初始化工作,例如初始化日志,检查集群一致性等。
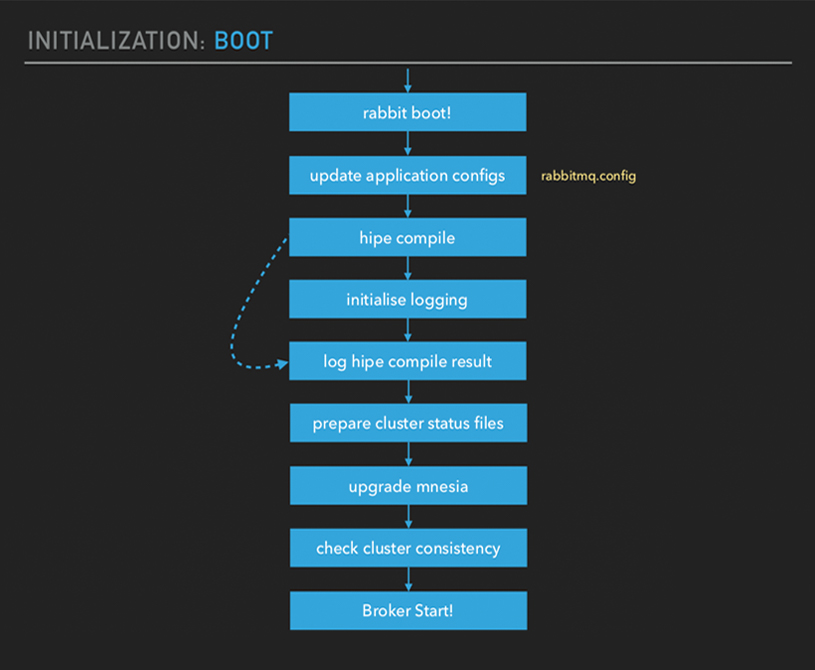
紧接着启动 broker , 加载插件,然后看到启动日志。
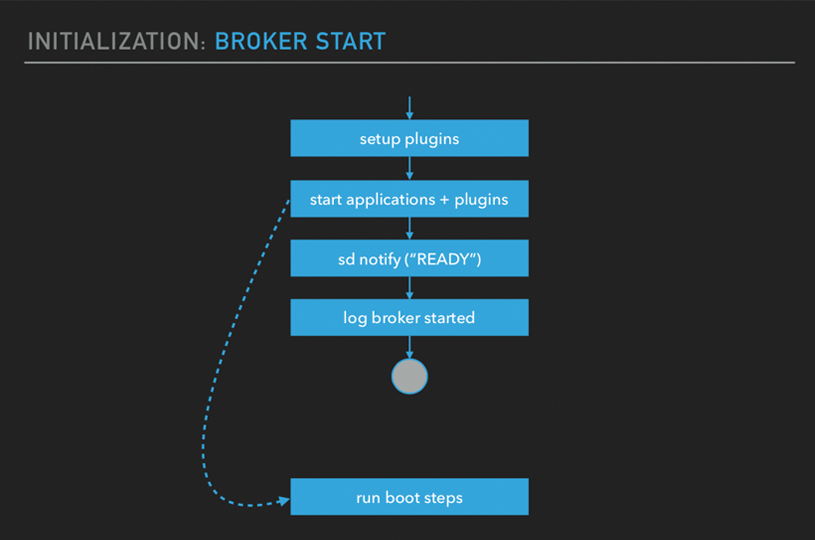
之后会初始化一些内部状态,比如开启认证,启动队列镜像节点,HA 节点,Policy 验证初始化,默认启动一个优先队列,运行报警进程,内存监控,节点监控,开启监听端口,初始化 Mnesia 数据库中的表,比如用户表等。
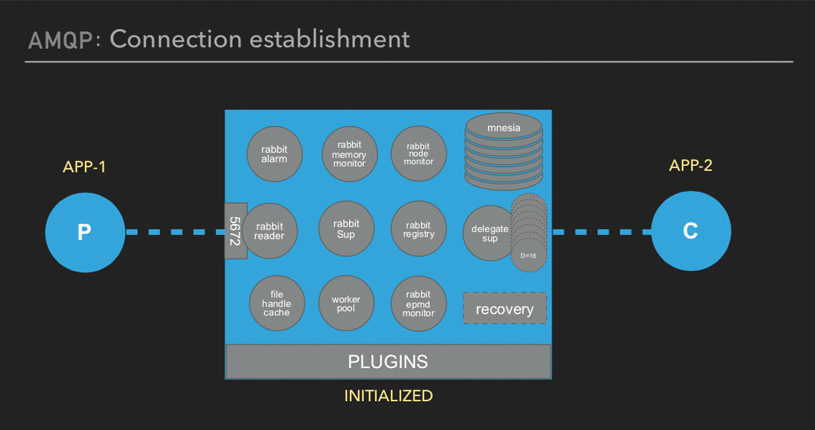
建立连接
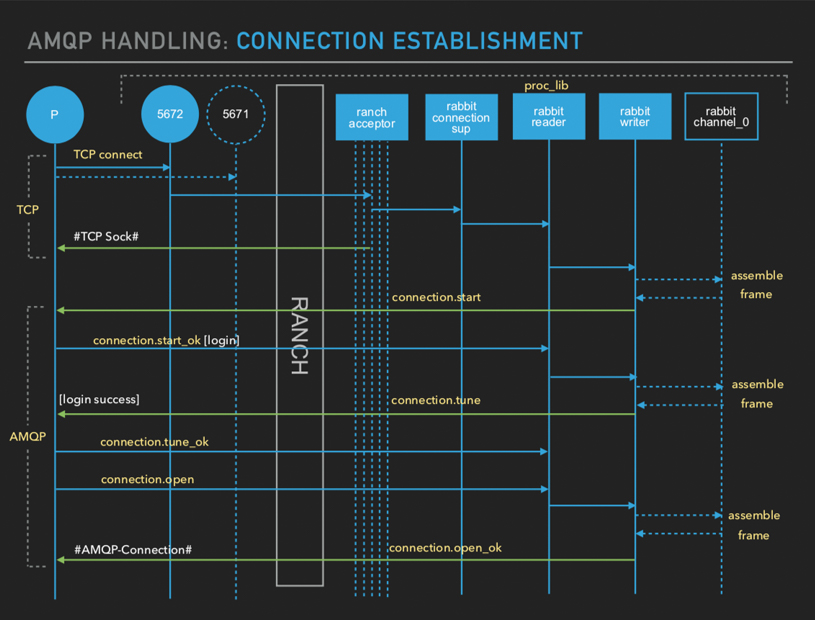
当客户端与 RabbitMQ 建立连接时,会经历两个阶段,一个是 TCP 握手,一个是 AMQP 握手。TCP 握手过程由 ranch acceptor 进程处理,这里说的进程都是指 erlang 进程。 ranch acceptor 进程是初始化时创建的默认 10 个,负责与客户端建立 TCP 连接,将连接交给 rabbit connection sup 进程,这个进程会创建 一个 rabbit reader 进程和一个 rabbit writer 进程,并给客户端返回 connection.start,然后 rabbit reader 进程等待客户端发来 AMQP 握手消息,AMQP 握手消息携带认证信息,认证成功返回 connection.tune,客户端收到后发送 connection.tune_ok,connection.open,服务端发送 connention.open_ok,客户端收到后 AMQP 连接建立。可以看到,这里每个连接都会开启一个读进程和写进程来处理连接,所以即使 erlang 进程轻量,也不应该一直创建连接,而是要尽量复用连接。
开启 Channel
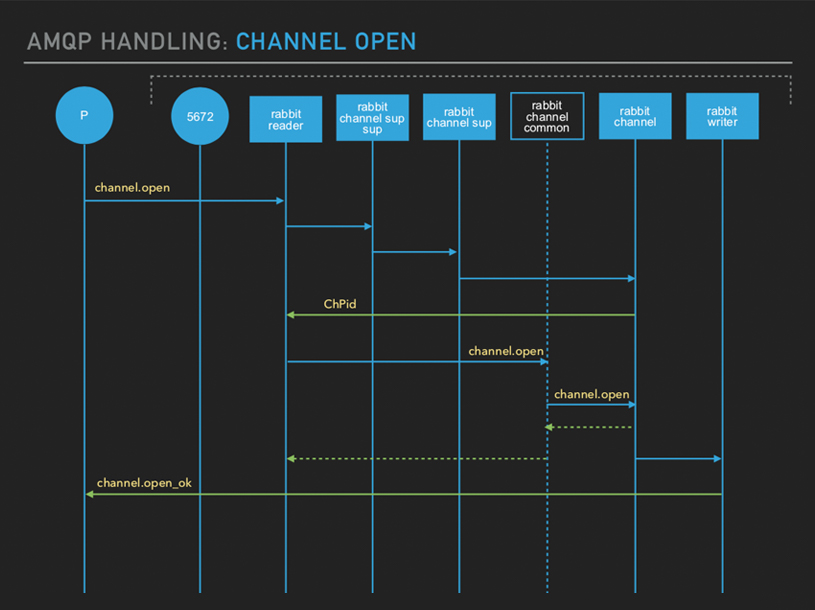
当客户端发起 channel.open 时,首先会交个 reader 进程处理,然后开启两个 channel sup 进程,这两个进程是分级的,二级 channel sup 进程会开启一个 channel 进程,然后返回 ChPid 给 reader ,reader 收到后给 channel common 发送 channel.open ,channel common 发送给 channel,最后由 writer 返回给客户端 channel.open_ok , Channel 创建成功。
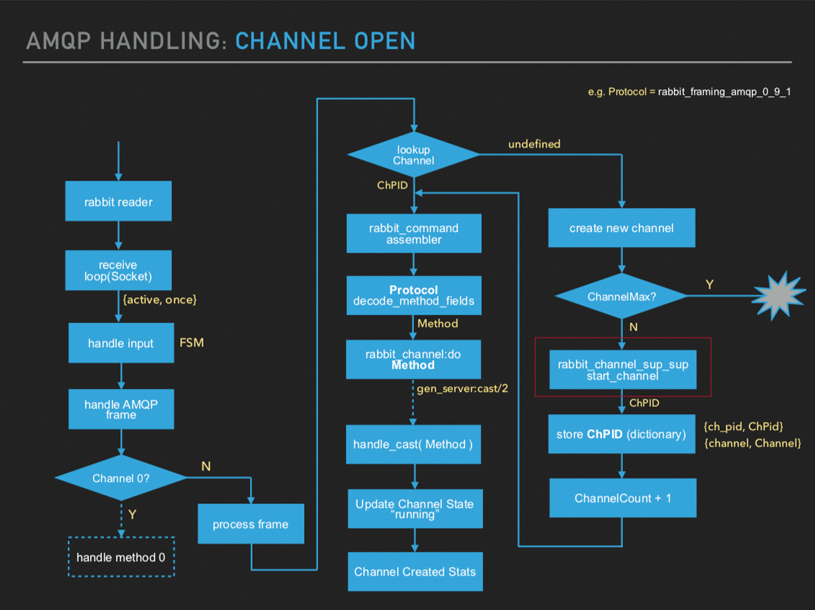
- 这里会检查是不是开启
channel 0, 因为channel 0是共用的,并且是在初始化阶段就创建的。 - 所有
channel的PID字典都会保存在reader进程的内存中,如果在内存中查不到才会重新创建。 - 会判断创建的
channel是否达到上限。
一个 channel 创建会同时创建很多的管理进程。如果使用 direct channel,那就只会创建一个 channel 进程和一个 limiter 进程,limiter 进程主要是实现 prefetch 功能,调节 channel 和 consumer 间的流量。
创建 / 声明 Exchange
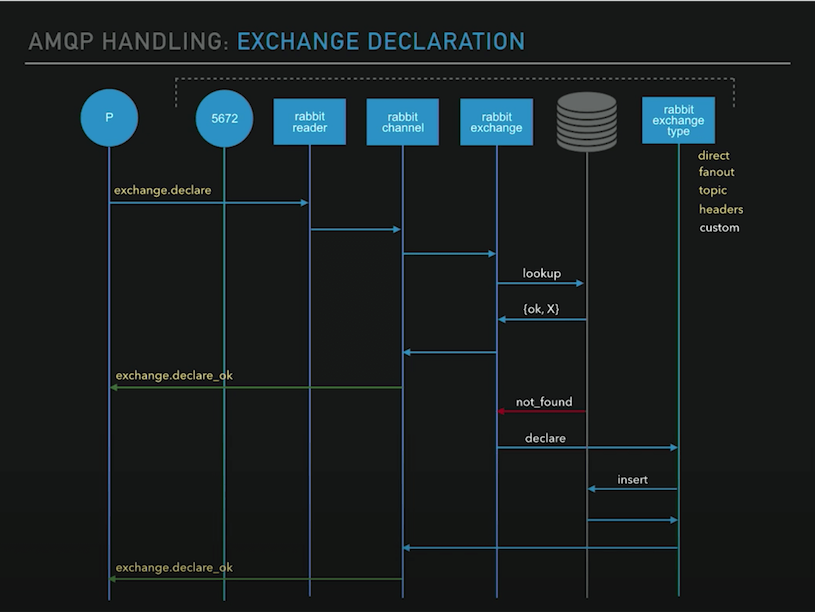
消息交换过程与 channel 创建类似,但是这里 exchange 的信息会存到数据库里。
创建 Queue
.oymxl51ecte.png)
创建队列时会首先在数据库中查找,如果已经存在并且 nowait 为 ture,则直接返回 queue.declare_ok,如果为 false 则会向代理进程发起 stat 命令,代理进程判断将命令发送到本地队列还是远程队列,队列返回其对应的状态信息,如果已经启动,返回 queue.declare_ok。如果在数据中不存在,则会走创建流程,会根据队列的类型,比如是否优先级,持久化创建队列。
Queue 绑定到 Exchange
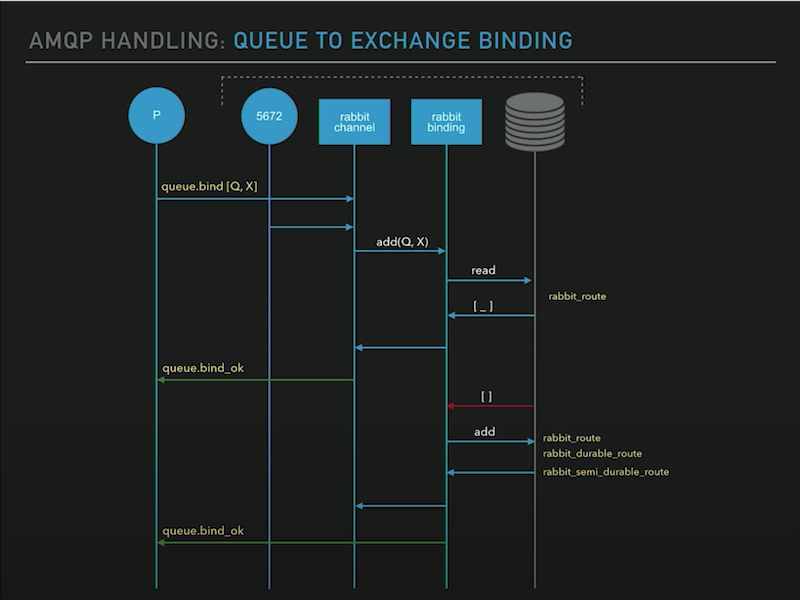
队列绑定到交换机会将绑定关系保存到数据库,有则直接返回,无则创建。
消费
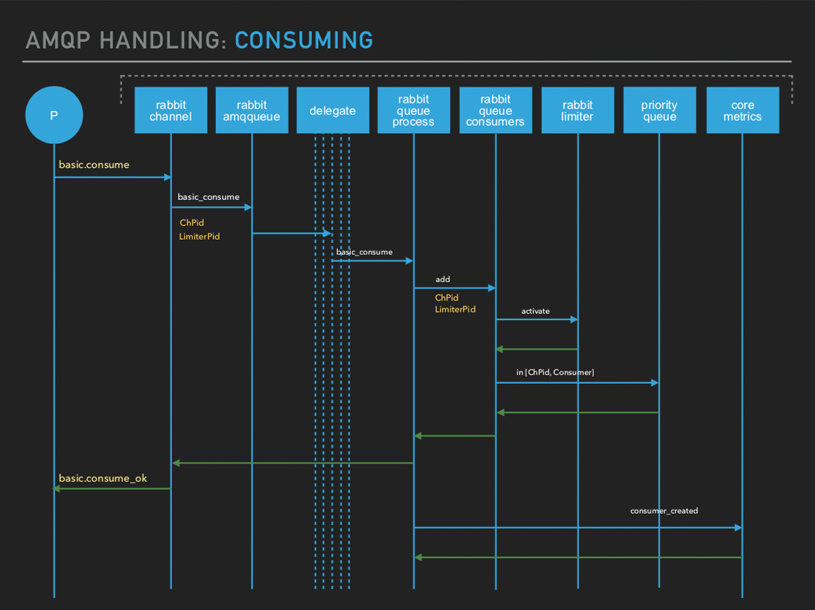
和创建队列时一样,basic.consume 命令会通过代理进程发往本地队列或远程队列,如果开启 prefetch 功能的话会开启 limiter 进程来控制流量,prefetch 就是消费者可以允许一定量的消息不用确认,用于提高消费的吞吐。同时每次消费是都会创建一个优先级队列,用来实现消费者优先级。
生产
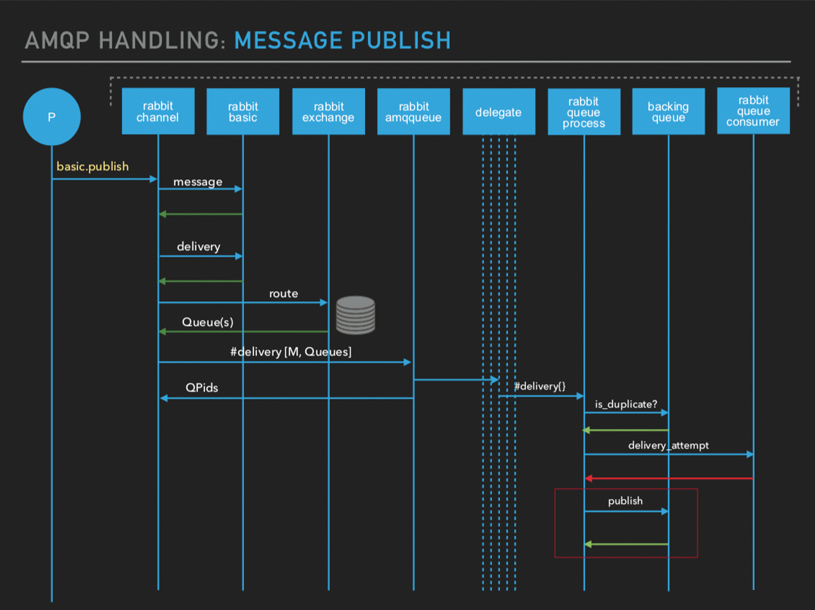
生产者发送消息时会首先根据 exchange 类型 routing key 等从数据库中取出相应队列的信息,然后通过代理进程发送到相应的队列进程,队列进程在真正后端队列中判断是否是重复,然后看有没有正在消费的消费者,如果有的话会直接发送给消费者,如果没有的话会通过消息存储把消息存储下来。
关于消息存储
- 不管是持久化还是非持久化的消息都有可以写入磁盘,持久性消息一到达后端队列就会写入磁盘,而非持久化的消息只有在内存有压力的时候,才会被写入磁盘,持久化的消息也会保留在内存中 (为了能更快把消息的发送给消费者),只有当有内存有压力的时候才会从内存中淘汰。处理磁盘写入,内存淘汰的这一层称为持久层。
- 持久层由两个部分组成,队列索引和消息存储。队列索引负责维护关于一个给定消息在队列中的位置,以及它是否已经被交付和确认。因此,每个队列有一个队列索引。消息存储是一个消息的键值存储,在服务器的所有队列中共享。消息(正文和任何元数据字段:属性和/或标题)可以直接存储在队列索引中,也可以写到消息存储中。
内存消耗
在内存压力下,持久化层试图尽可能多地写入磁盘,并尽可能多地从内存中删除。然而,有一些东西必须留在内存中。
- 每个队列为每个未确认的消息维护一些元数据。如果消息的目的地是消息存储,那么消息本身可以从内存中删除。
- 消息存储需要一个索引。默认的消息存储索引为存储中的每条消息使用少量的内存。
消息嵌入到消息索引中
优点:
- 消息可以在一次操作中写入磁盘,而不是两次;对于消息大小很小的消息,可以减少写入次数,提升性能。
- 写入队列索引的消息不需要在消息存储中存储,因此从内存中删除时只需删除索引,不需要再删除消息存储。
缺点:
- 如果消息很大,那么内存占用很大。
- 如果一个消息被交换机路由到多个队列,那么该消息需要写入多个队列索引。如果这样的消息被写入消息存储,则只需要写入一份副本。
- 未确认的消息索引将一直保存在内存中一直占用内存。
集群
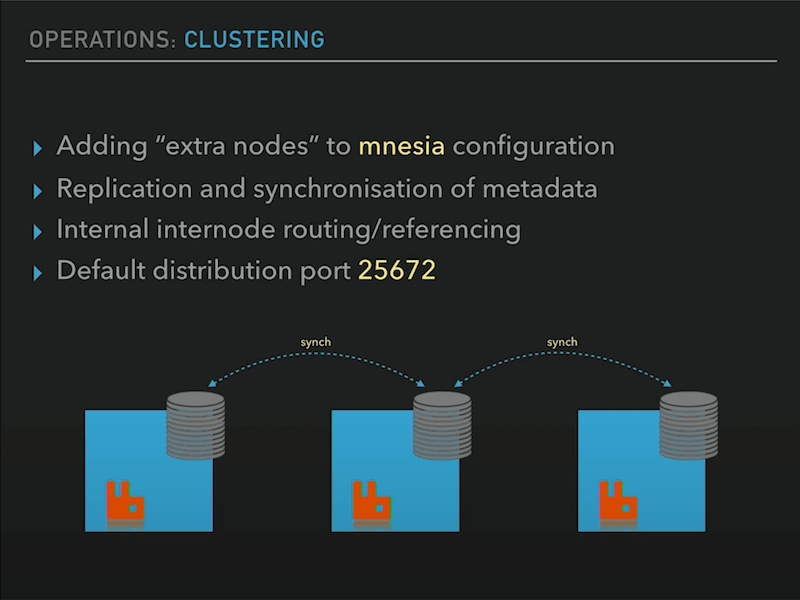
一个节点加入集群,Mnesia 数据库的配置会更新,Mnesia 存储引擎将同步节点状态,路由表到其他节点。
高可用
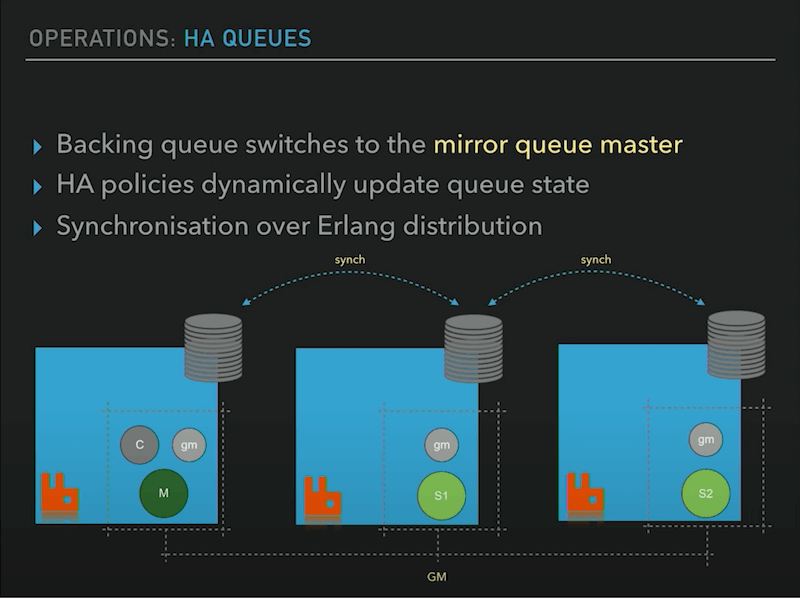
当设置为高可用时,普通队列就会变为镜像队列主,队列状态将被动态更新,然后所有的同步操作都将由 Erlang 进程处理。
主队列不能直接与 gm 进程交互,而是要使用协调者,每个从队列都有一个 gm 进程,彼此交互,发布,处理集群事件,复制,同步集群数据。