Zookeeper
Contents
ZooKeeper 是业界广泛使用的分布式协调服务,在服务发现,分布式配置管理,分布式锁等场景中广泛使用。这里根据6.824课程对其原理做一个简单的梳理。
线性一致性
在分布式场景中,一致性是一个绕不开的话题,要想知道 ZooKeeper 的一致性级别,首先要了解线性一致性的概念。
线性一致性的定义是:一个系统的执行历史是一系列的客户端请求,或者是来自多个客户端的多个请求。如果执行历史整体可以按照一个顺序排列,且排列顺序与客户端请求的实际时间相符合,那么它是线性一致的。
线性一致性有两个约束条件:
- 一个操作在另一个操作开始之前完成,那么其在操作历史中必须排列在另一个的后面。
- 如果一个读操作看到了一个写操作写入的值,那么其在操作历史中必须排列在写操作的后面

上面的例子中,竖线表示一个操作的开始和结束,Wx1 表示写入 x 的值为 1,Rx1 表示读到 x 的值为 1,通过线性一致性的两个约束画出其执行先后顺序,可以看到,第一个例子是可以找到一组操作的顺序满足线性一致性的条件的,而第二个例子中出现了循环,无法找出一组满足线性一致性的操作,所以第二个例子不满足线性一致性。
ZooKeeper 解决了什么问题
-
为构建分布式系统提供通用
API。通过
ZooKeeper提供的API, 开发者可以自己实现分布式协调,分布式配置,分布式锁等分布式系统,极大的减轻了构建分布式应用的痛苦。 -
机器数线性增加,性能线性增加。
ZooKeeper是一个多副本容错的分布式协调服务,那么副本数增加,其性能会线性增加吗?ZooKeeper的多副本复制协议使用的ZAB协议,和Raft的实现是类似的,都需要leader将日志复制到follower, 经过大多数节点确认后才提交日志。如果加入更多的服务器,可以确定leader会成为瓶颈,因为leader需要处理每一个请求,并将日志复制给follower,新加入的机器并没有完成任何实质性的工作,在这种情况下加入机器反而会使leader负载增加,处理性能下降。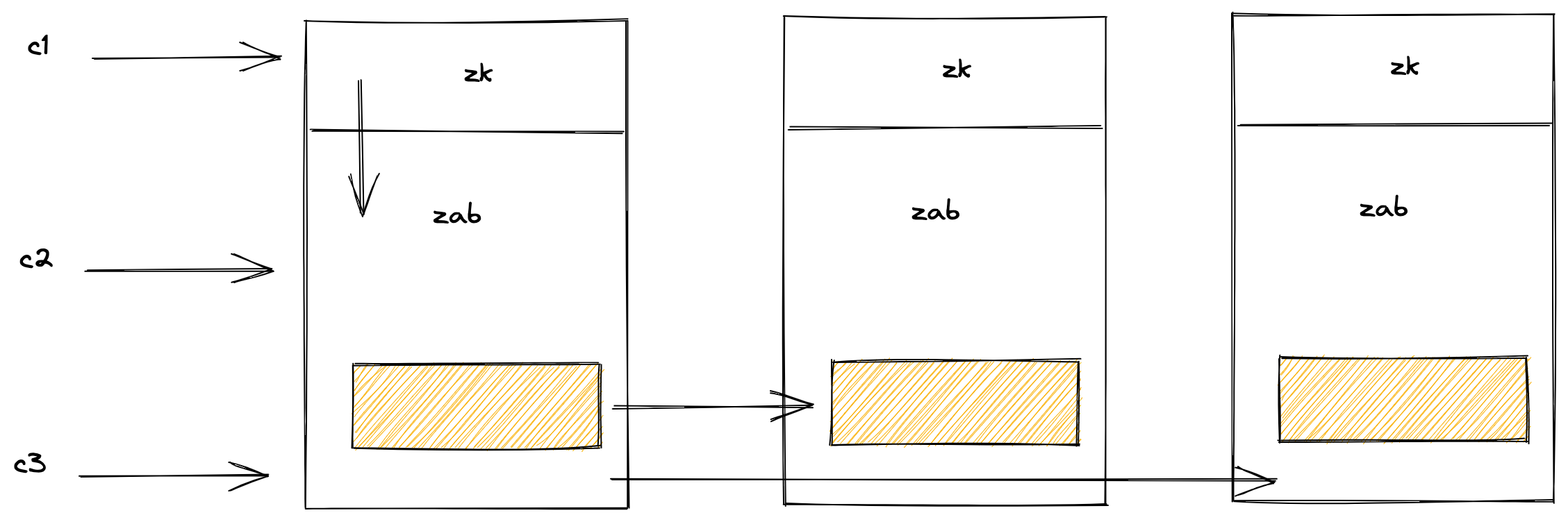
ZooKeeper的实现中读请求是可以由follower处理的,我们知道如果读请求由follower处理那么就有可能读不到最新的数据,那么ZooKeeper是怎么做的呢?
对于读请求,每次读副本上的数据都会给客户端返回一个 zxid 表示当前读到的位置,如果当前读的副本宕机了,那么下次读其他副本时会根据 zxid 来确定要读取的位置,如果要读的位置当前还没数据,那么会等待这个位置同步到数据返回,所以对于单一的客户端而言可以保证其读写都是线性一致的。
ZooKeeper 一致性保证
-
对于写请求保证线性一致性
-
FIFO Client Order
对于单个客户端来说保证操作顺序是先进先出的,即单个客户端保证线性一致性
看一个分布式系统配置更改的例子,对配置更改是一系列的操作,必须保证其原子性,通过判断 “ready” 路径是否在来判断是配置是否正在被更改,这里列举两种情况。

第一种,exists("ready") 在 write("ready") 后执行,若 exists("ready") 返回成功,说明已经 ready 路径已经存在,由于写线性一致性保证可以保证 write f1, write f2 发生在 write("ready") 之前,由单客户端线性一致性保证,可以保证 read f1,read f2发生在 exist("ready") 之后,所以 read f1, read f2 一定是发生在 write("ready") 之后,这种情况下可以保证 读配置和写配置操作是原子的。
第二种,exist("read"),read f1 发生在 delete("ready") 之前,而 read f2 发生在 write("ready") 之后,这种情况下操作就不是原子的了,为了解决这个问题,需要在 exist("ready") 中加入 watch 参数,一旦发生修改则会接收到通知,客户端放弃 read f2 来保证读取的原子性。
ZooKeeper API
-
create(path, data, flags):创建在路径path下的znode,data是要存放的数据,并返回新znode的名称。标志flags可以让客户端选择znode的类型:regular(常规的),ephemeral(临时的),sequential(顺序的)。 -
delete(path, version): 删除给定路径和版本下的znode。 -
exists(path, watch):如果有路径名路径的znode存在,返回true,否则返回false。watch允许客户端在znode上设置监视器。 -
getData(path, watch)返回与znode相关的数据和元数据如版本信息。watch标志的工作方式与exists相同,但是如果znode不存在的话,zookeeper就不设置watch。 -
setData(path, data, version):如果版本号是version, 写入数据data[]到znode路径。 -
getChildren(path, watch):返回一个znode的子节点集。 -
sync(path): 把所有在sync之前的更新操作都进行同步,达到每个请求都在半数以上的ZooKeeper Server上生效。path参数目前没有用。
ZooKeeper API 应用
计数器
|
|
类似 CAS 操作,但是这里有一个问题是当有 n 个客户端同时需要增加计数器时,每个客户端最多可能需要执行 n 次操作才能操作计数器,其复杂度是 $O(n^2)$。
非可扩展锁
|
|
这里的问题和计数器的例子一样,当有 n 个客户端获取锁时,如果一个客户端获取了锁,其余 n-1 会阻塞在 exists,当持有锁的客户端释放锁时,n-1个客户端同时被唤醒,同时发起 create 请求,其复杂度也是 $O(n^2)$。这种现象称作羊群效应(Herd Effect)。
可扩展锁
|
|
每个客户端会创建一个带有递增序列号的 znode,只有序列号最小的客户的端可以获取到锁(FIFO),其他客户端不是当前最小序列号只会 watch 它序列号之前的一个 znode,所以一旦一个锁被释放,唤醒的只是等待在下一个序列号上的客户端,巧妙地解决了羊群效应问题。
另外这里的锁并不保证原子性,如果一个客户端需要原子执行一系列操作获取了锁,在执行了某些操作后,客户端意外退出了,此时 ZooKeeper 会释放锁,其他获取到锁的客户端会读到脏数据。所以使用 ZooKeeper 锁时需要注意处理这种情况,当获得锁时,确认之前的客户端是否故障了,如果是的话,需要修复数据。因此ZooKeeper 锁适合使用在保护一些不太重要的数据。
总结
ZooKeeper 精巧的 API 设计为开发者提供了独立易用的分布式协调服务,解决了分布式协调服务在读多写少场景下水平扩展问题。当然要用好 ZooKeeper 就需要对其 API 原理有足够了解,才能灵活应用到不同的应用场景中。